Evaluating with Objective Metrics
Transformer Lab provides a suite of industry-standard objective metrics supported by DeepEval to evaluate model outputs. Here's an overview of the available metrics:
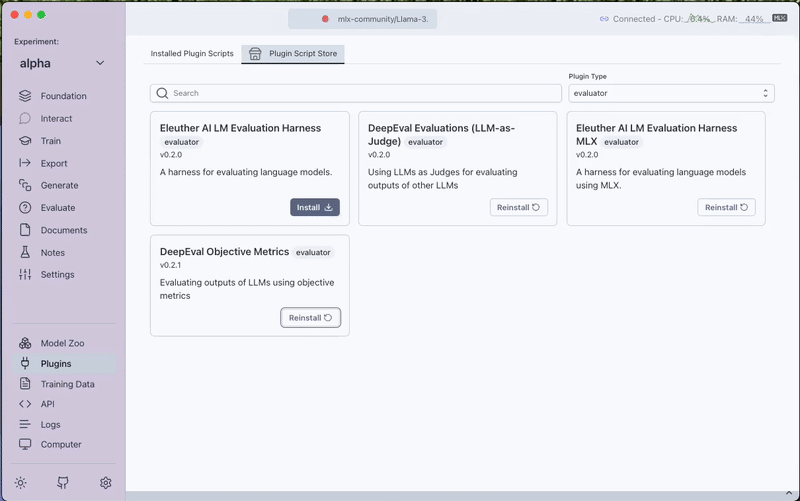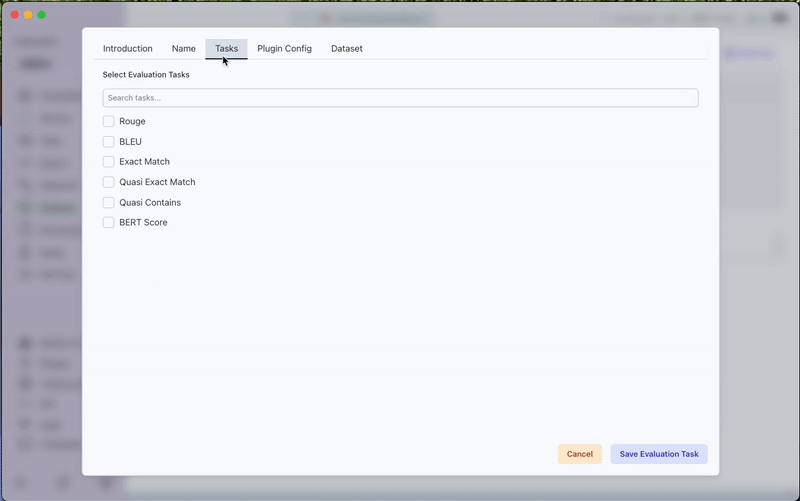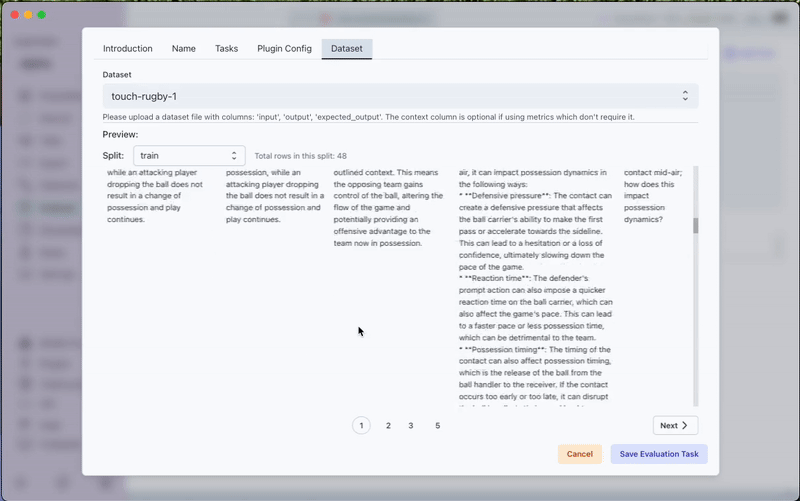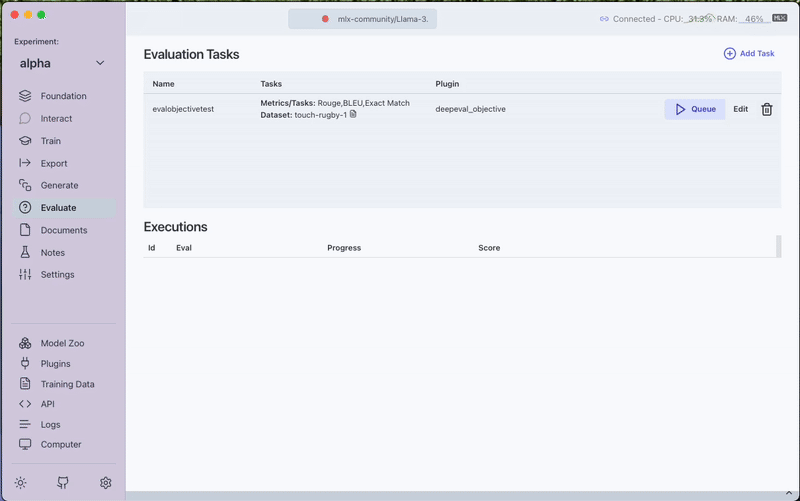
- Rouge: Evaluates text similarity based on overlapping word sequences
- BLEU: Measures the quality of machine-translated text by comparing it with reference translations
- Exact Match: Checks for perfect string matches between output and expected output
- Quasi Exact Match: Similar to exact match but allows for minor variations in capitalization and whitespace
- Quasi Contains: Checks if the expected output is contained within the model output, allowing for minor variations
- BERT Score: Uses BERT embeddings to compute similarity between outputs
Dataset Requirements
To perform these evaluations, you'll need to upload a dataset with the following required columns:
input: The prompt/query given to the LLMoutput: The actual response generated by the LLMexpected_output: The ideal or reference response
Step-by-Step Evaluation Process
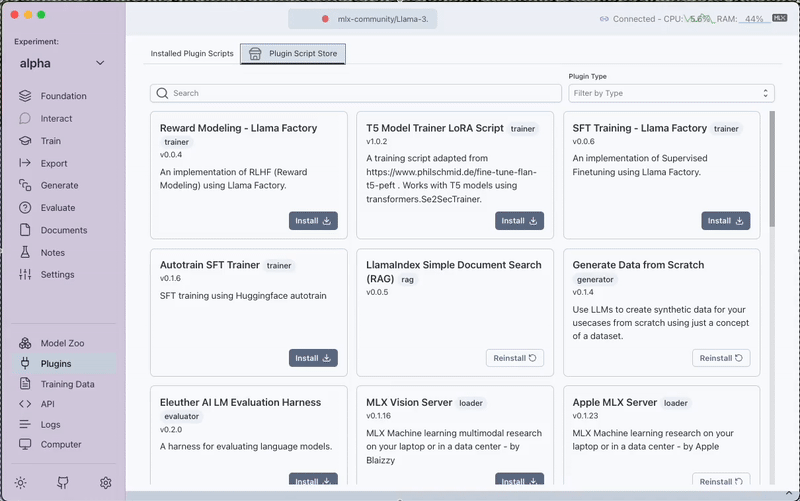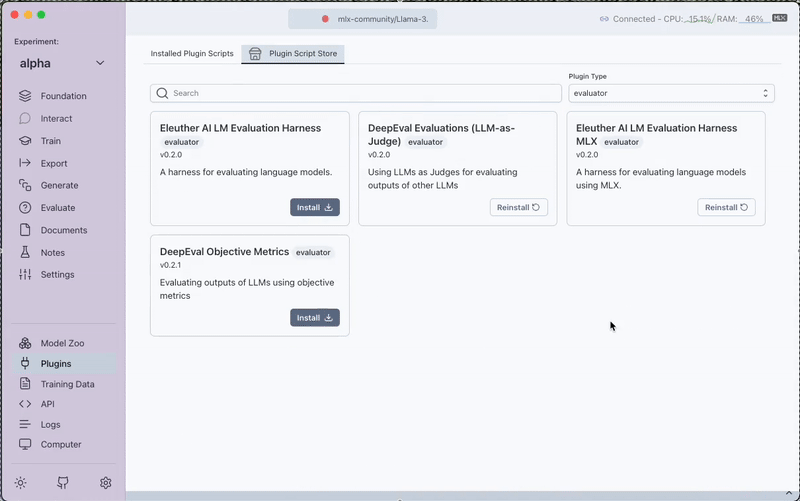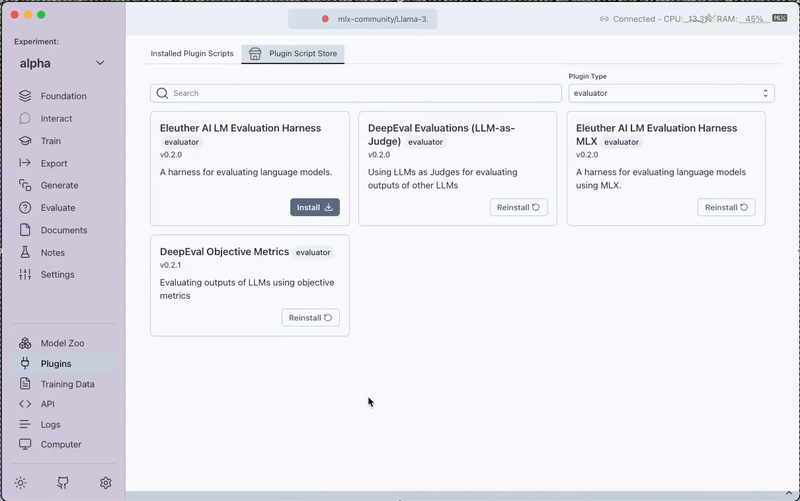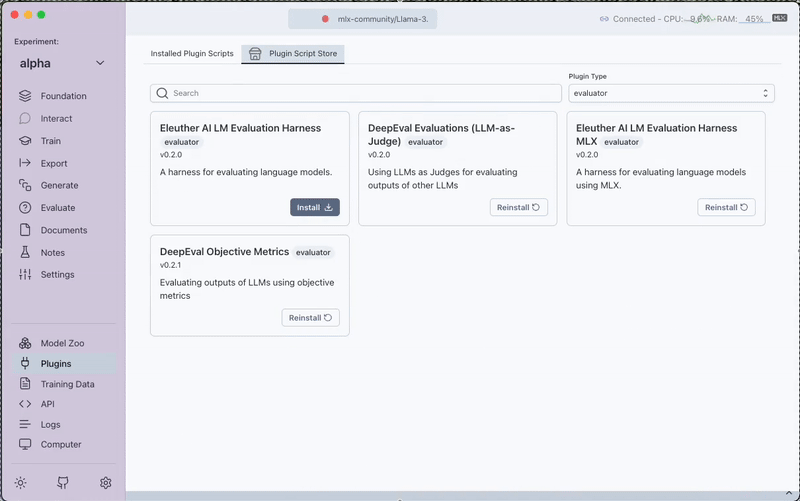
1. Download the Plugin
Navigate to the Plugins section and install the Objective Metrics plugin.
2. Create Evaluation Task
Configure your evaluation task with these settings:
a) Basic Configuration
- Provide a name for your evaluation task
- Select the desired evaluation metrics from the Tasks tab
b) Plugin Configuration
- Set the sample fraction for evaluation
- Select your evaluation dataset
3. Run the Evaluation
Click the Queue button to start the evaluation process. Monitor progress through the View Output option.
4. Review Results
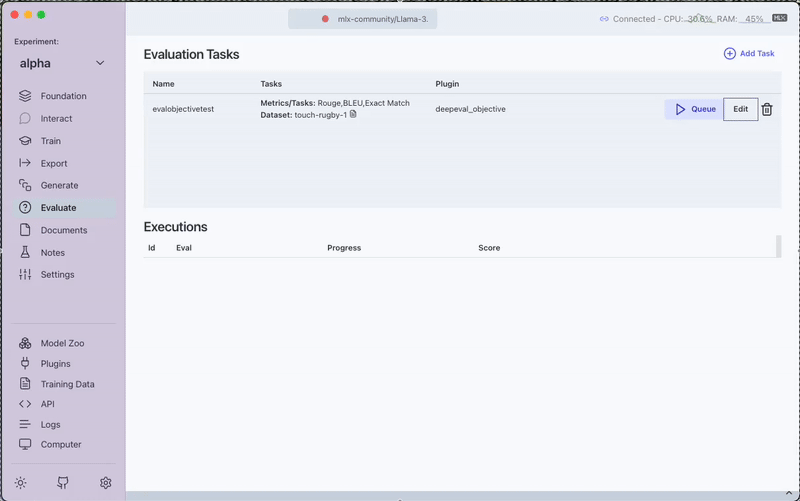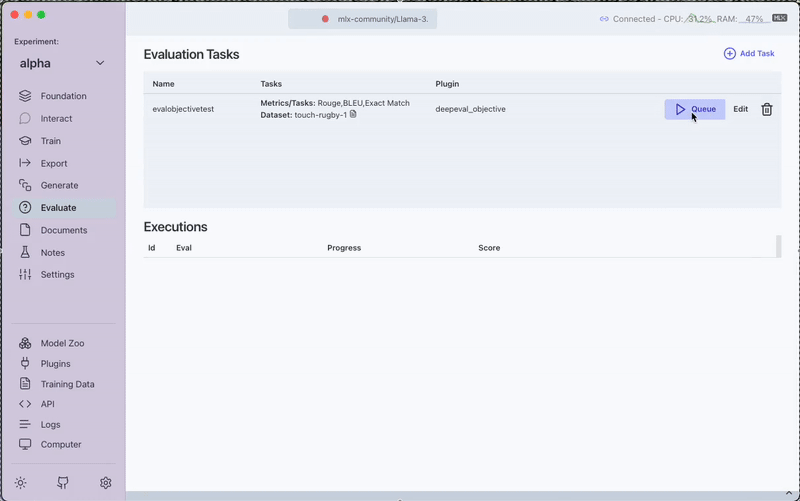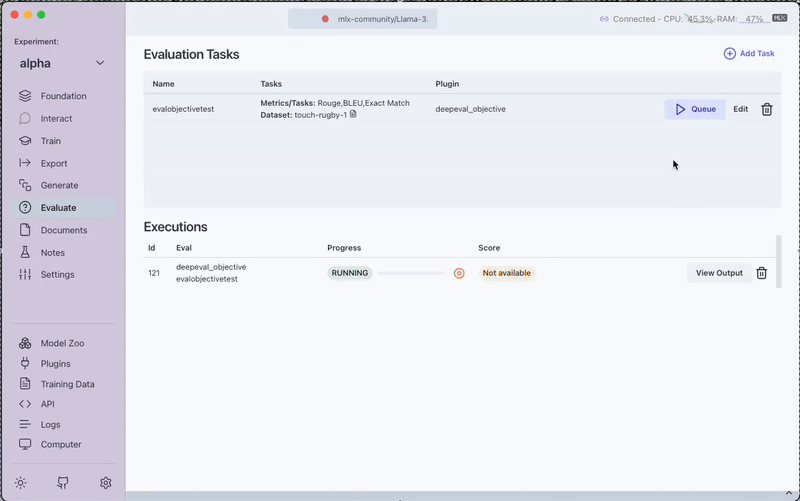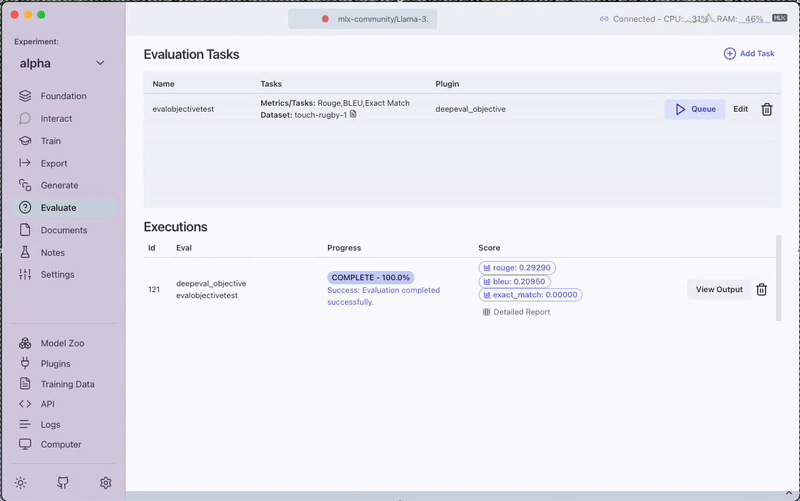
After completion, you can:
- View the evaluation scores directly in the interface
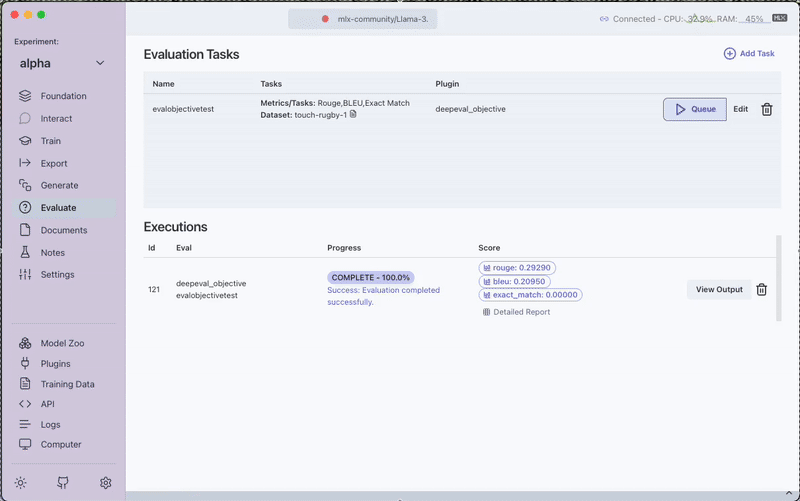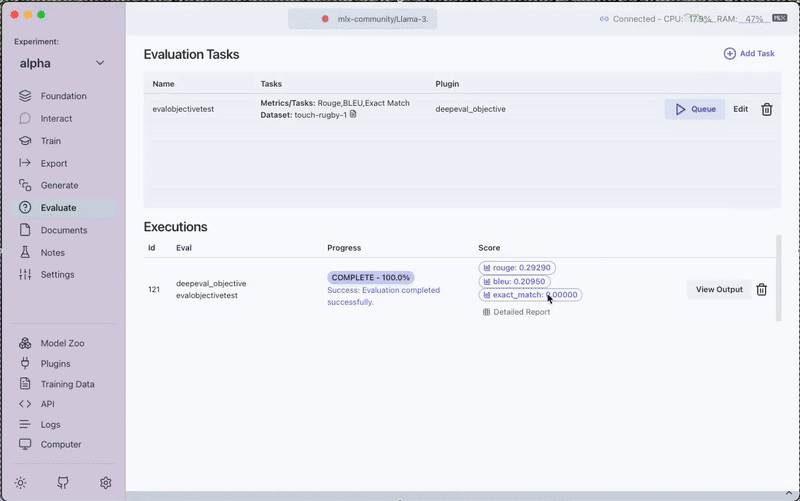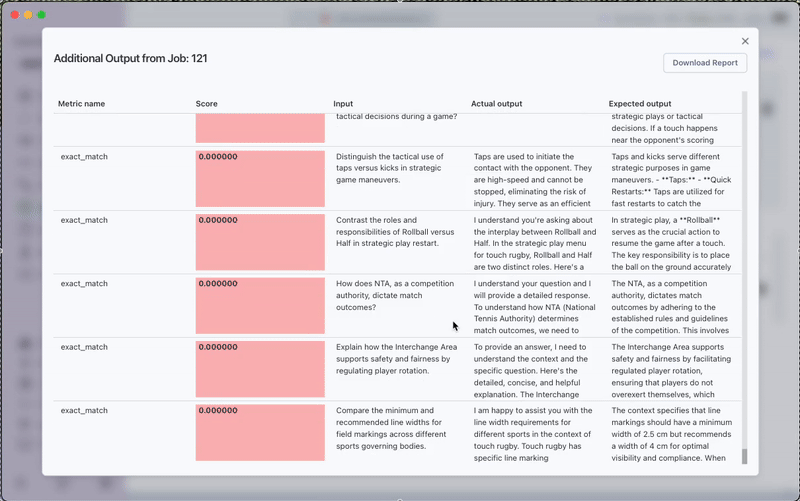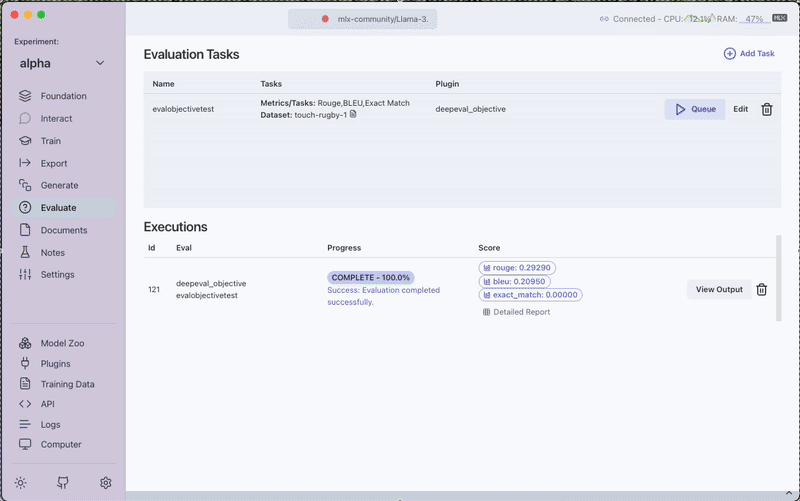
- Access the Detailed Report for in-depth analysis
- Download the complete evaluation report