Diffusion LLM Evaluator
Use the Diffusion LLM Evaluator plugin to score BERT, Dream, and LLaDA text-diffusion models with the EleutherAI LM Evaluation Harness. The plugin mirrors the workflow of other Harness evaluators but exposes dllm-specific decoding controls (diffusion steps, CFG, Dream sampling, etc.) so you can compare apples-to-apples with your training configurations.
1. Install the Evaluator Plugin
- Open the
Pluginstab. - Filter by
Evaluatorand install Diffusion LLM Evaluator. - Ensure your workspace has CUDA GPUs—the harness backend and dllm runners currently target CUDA only.
2. Select a Model to Evaluate
- Go to the Foundation tab and pick the adaptor or fused model you trained earlier (BERT / Dream / LLaDA).
- Click Create Evaluation Task and choose the Diffusion LLM Evaluator as the plugin.
Dataset Tab?
Harness benchmarks ship their own datasets, so you can leave the Dataset tab empty. Transformer Lab handles all prompt/answer fetching for the task you choose later.
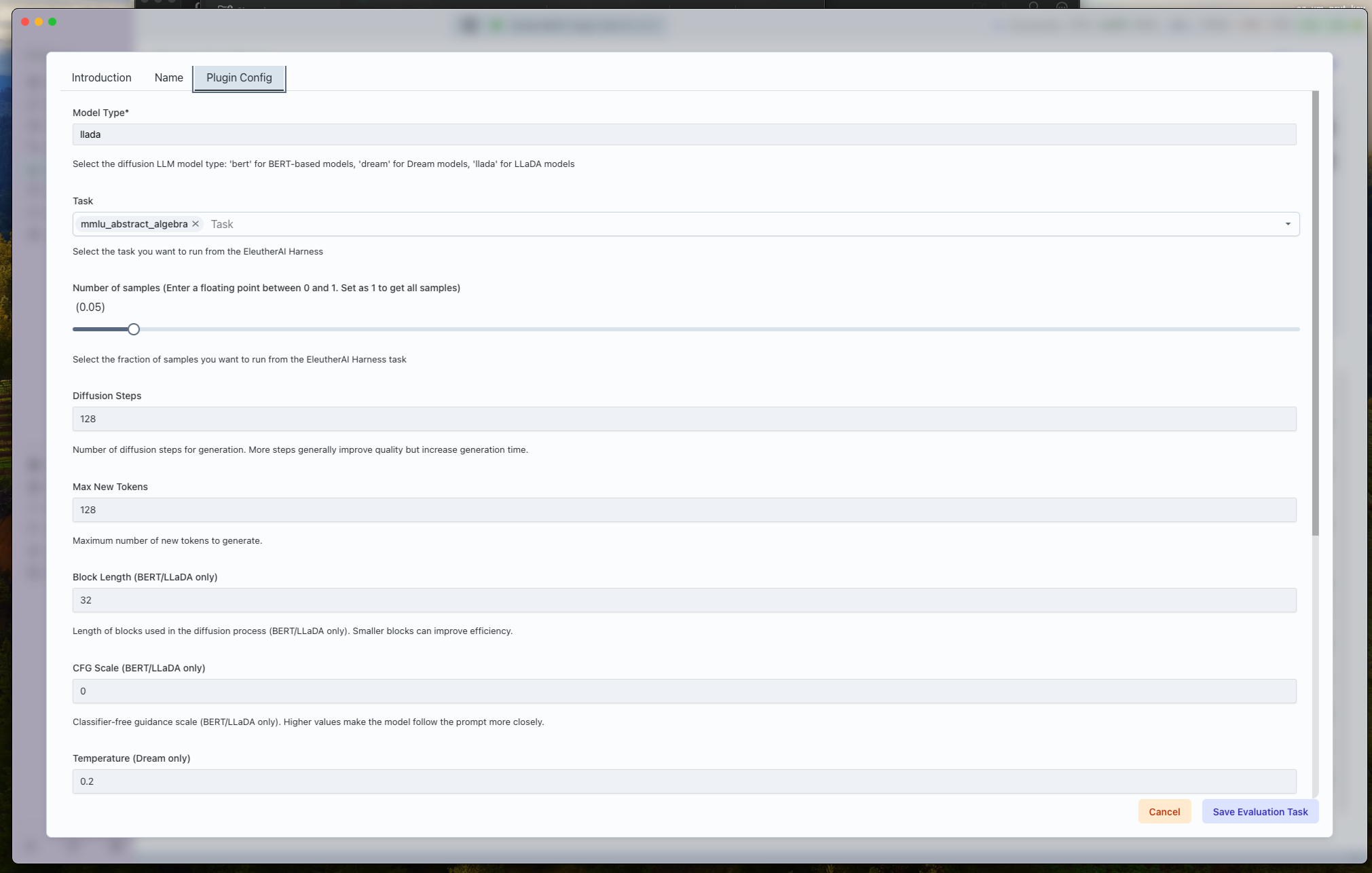
3. Configure the Evaluation Task
Fill in the Template/Task Name and move to the Plugin Config tab. The fields mirror the JSON schema in your index.json and map directly to EleutherAI Harness arguments.
Model + Task Selection
- Model Type (
model_type): Pick the architecture family for the adaptor you selected (bert,dream, orllada). This toggles which dllm runner spins up. - Tasks (
tasks): Choose one benchmark from the Harness list (ARC, HellaSwag, MMLU categories, GSM8K, HumanEval, etc.). Each task runs separately; duplicate the template if you want a sweep. - Limit (
limit): Fraction of the task to evaluate (0.05–1.0). Keep it at1.0for leaderboard-quality scores; drop lower for sanity checks. - Num Few-shot (
num_fewshot): Add K-shot demonstrations for tasks that support it. - Apply Chat Template: Enable to wrap prompts using the model’s chat formatting before sending them to the evaluator.
Diffusion Generation Controls
- Steps (
steps): Number of diffusion steps per completion (1–2048). - Max New Tokens (
max_new_tokens): Upper bound on output length. - Block Length / CFG Scale: Available for BERT and LLaDA models to control block sampling and classifier-free guidance.
- Temperature / Top-p: Dream-only sampling knobs for controllable diversity.
Advanced Accuracy Options
- Monte Carlo Samples (
mc_num): Number of samples per loglikelihood evaluation. Increase for stable estimates on generative tasks.
After reviewing everything, click Save Evaluation Template.
4. Queue and Monitor the Evaluation
- Open the template drawer and hit Queue.
- The evaluator will:
- Load the selected adaptor and harness task definition
- Run inference with your diffusion sampling settings
- Aggregate metrics from the EleutherAI Harness report
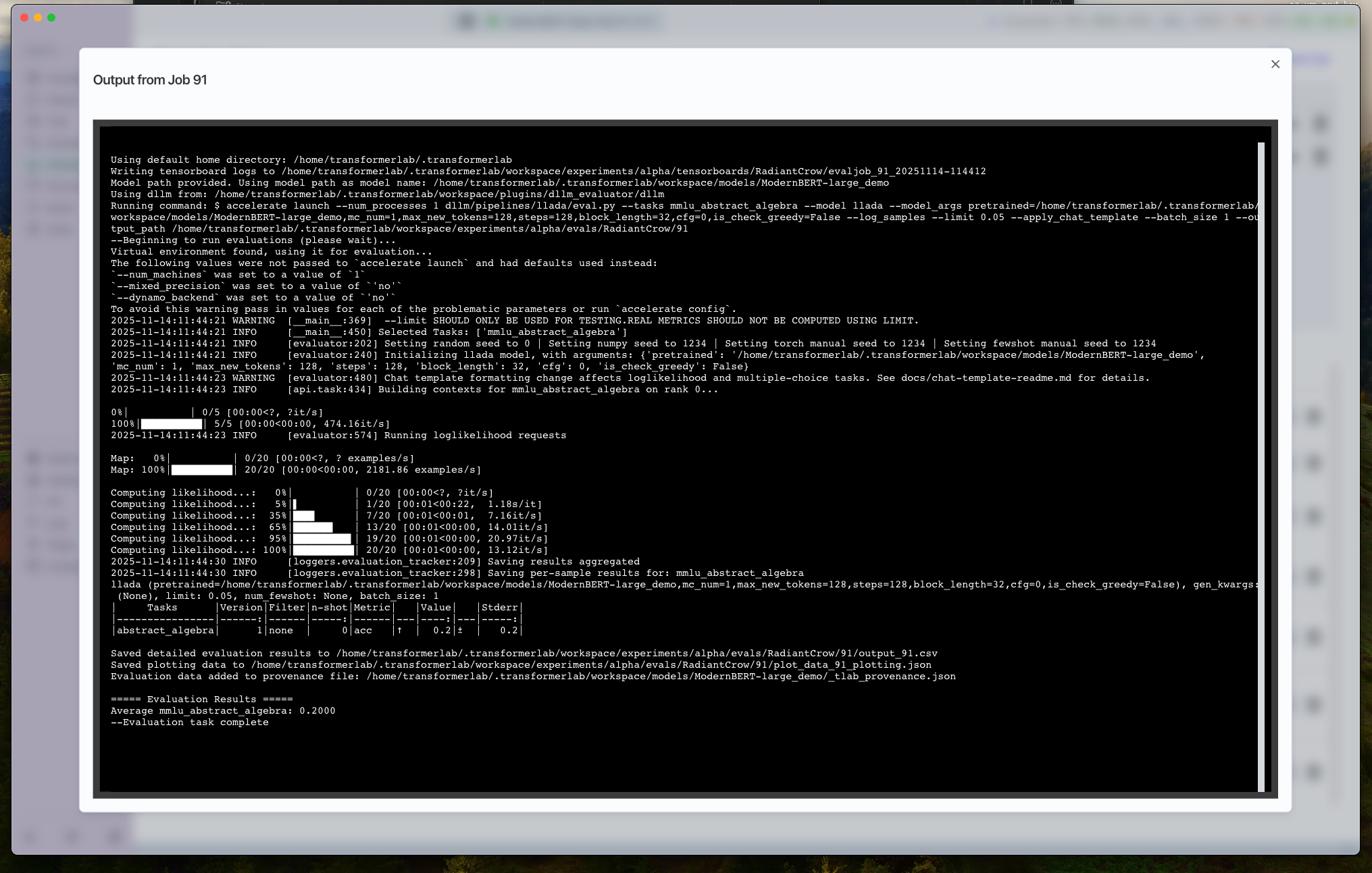
5. Review the Results
- Job Output: Inspect the live log stream for per-sample scores, harness status, and any dllm warnings.
- Results Reports: You can view the results reports with your run and also compare the evaluation run to other evaluation runs under the Evaluate tab.
- Foundation Tab: Metrics are attached to the evaluated model under provenance so you can quickly compare.
Tips for Reliable Harness Runs
- Match Training + Eval Settings: Re-use the same model type, CFG, and temperature settings you logged during training for apples-to-apples comparisons.
- Start with Smaller Limits: Validate script wiring with
limit = 0.1before paying the cost of full evaluations. - GPU Utilization: Evaluations parallelize over CUDA devices just like training; keep other heavy jobs paused to avoid OOMs mid-run.