A Universal Post-Training Improvement for Open Audio Models



A robustness study of open autoregressive codec-TTS: a tiny test-time trick removes catastrophic failures across four models and three codecs, and we can distill it back into the model (paid once in training, not on every generation) where it actually matters.
Quick summary: Open source text-to-speech models perform well most of the time but occasionally fail badly: going silent, looping a syllable, or saying something that isn't the text. We found a simple technique that vastly improves quality: generate a few takes, let an ASR model pick a clean one, and the failures all but disappear. The method is easy to apply, it works on every model and codec we tried (four models, three codecs), and we can bake the behaviour back into the model so a single normal generation inherits most of it, but only where the model was actually failing. We share some samples of our results below, and we also report the things that didn't work, because they're the useful part.
If you have played with open neural-codec text-to-speech, you have probably heard this: most sentences come out clean and natural, and then, with no warning, one comes out as half a second of silence, or a word looped five times, or a confident rendering of a sentence you did not type. The model didn't get worse; the very next sample of the same sentence is usually fine. It just fails, stochastically, on some fraction of generations. For a demo that is charming. For anything you would ship, it is disqualifying.
We chased this failure mode on Llasa-1B (a LLaMA-style language model over the XCodec2 speech codec) and then on three other open systems. The short version: the failures are real and frequent, they are cheap to remove at test time, and the fix generalizes far better than we expected. The longer version has a satisfying amount of "we were wrong about that" in it, which is why it is worth writing down.
First, you have to be able to measure it
Word error rate is the obvious metric, and it is a trap. Early on we wanted to study robustness on numbers and dates, and WER buried the effect entirely under digit-versus-word formatting noise ("$5" vs "five dollars" vs "5 dollars"): the canonicalization artifacts were bigger than the thing we were trying to measure. So we stopped trying to grade quality with WER and instead defined a blunt, format-robust catastrophic-failure flag: a generation fails if it drops out (almost no speech tokens, or the ASR transcript is one word or less) or if it collapses (word error rate above 0.5 against the reference). Run the audio back through Whisper, apply that rule, done.
Concretely, a single generation counts as a catastrophic failure if either of two things is true: it is a dropout (fewer than 25 decoded speech tokens, or an ASR transcript of one word or less), or it is a collapse (WER(transcript, reference) > 0.5). One flag, 0 or 1, per generation. It is deliberately coarse: it does not care whether speech is beautiful, only whether it is catastrophically broken, and that bluntness is exactly what makes it stable across models and codecs.
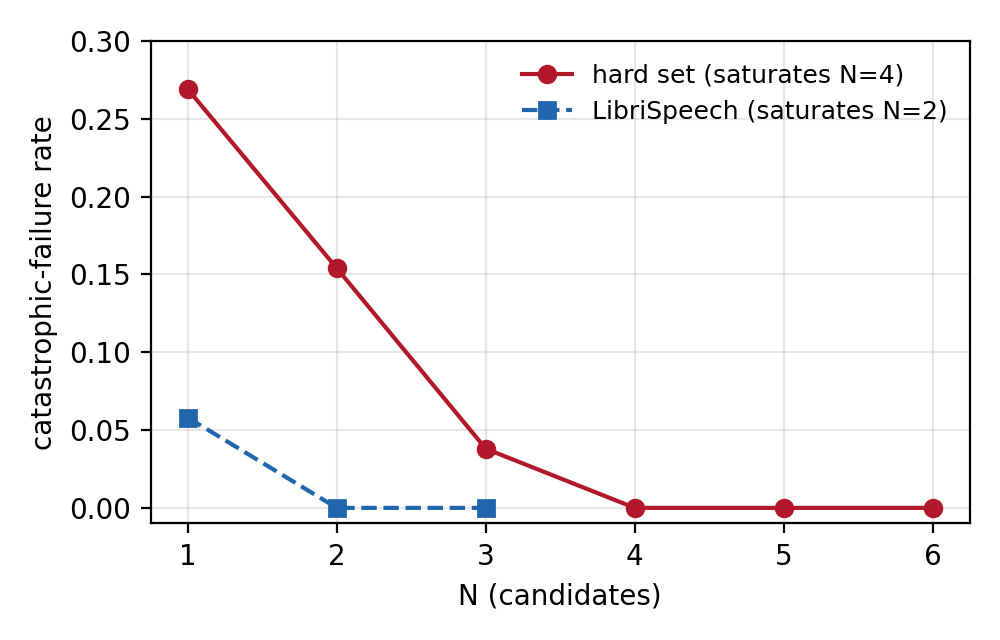
On Llasa-1B this flag fires on a meaningful fraction of generations: about a third of all attempts on a broad evaluation (≈0.36, including deliberately adversarial rare-word and number/date prompts), around 0.27 on the hard, hand-written set we use for the robustness experiments, and even on ordinary read-aloud prose (LibriSpeech) it is in the 5–10% range. That is the problem in one number.
The fix: let the model check its own work
The remedy is almost embarrassingly simple. Sample a few candidates for a prompt, transcribe each with ASR, and keep the one that isn't broken. A prompt only "fails" under best-of-N if all N candidates are catastrophic, so the failure rate is a product of per-candidate failures and can only go down as N grows.
It goes down fast. On the hard set, the failure rate falls from 0.27 single-shot to zero (no observed failures) by N=4. On LibriSpeech it is gone by N=2. The model is almost always capable of a clean take; it just doesn't always produce one on the first try, and a cheap verifier is enough to find the good one.
Hear it
Here is what that looks like for a single prompt, "The morning train arrived exactly on time." The first take is a dropout: Llasa-1B ran on for tens of seconds producing only silence (clip trimmed below), so the ASR transcript comes back empty and it scores as a catastrophic failure. A later take, the one self-verification keeps, is clean and correct.
Before (a raw single-shot generation, dropout to silence):
After (the self-verified take for the same prompt):
The result we did not expect is how well this travels. We ran the exact same procedure on three more open systems spanning three different neural codecs: Orpheus-3B (over the SNAC codec), Sesame's CSM-1B (over the Mimi codec), and a larger Llasa-3B. Best-of-N reduced catastrophic failures on every one of them.
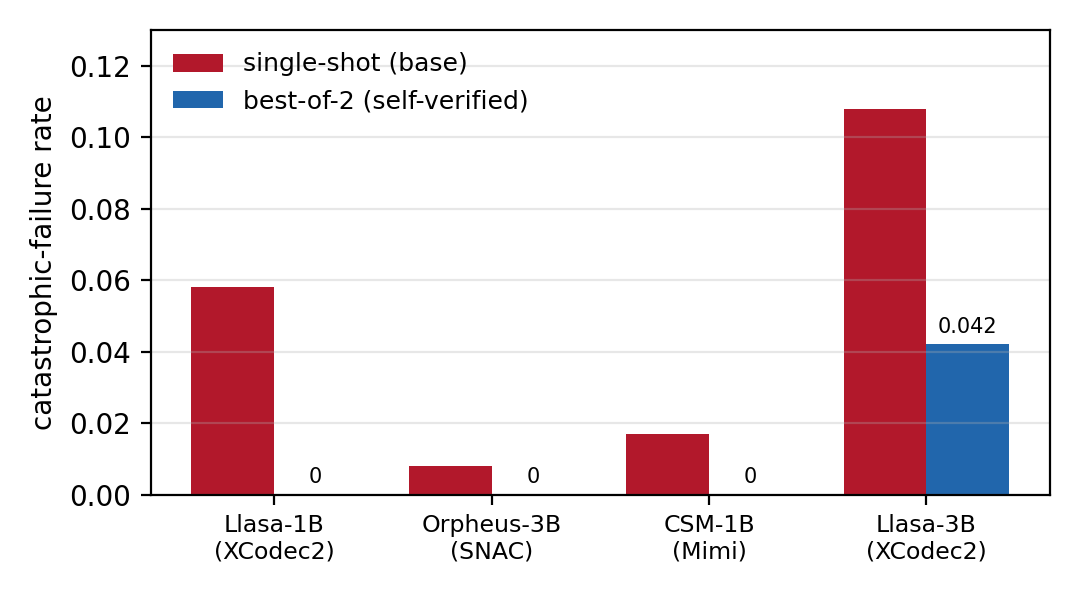
Three of the four models hit the floor (no observed failures) by just N=2. That the same trivial verifier works across single-stream codec tokens (XCodec2), flattened residual-vector-quantization tokens (SNAC), and hierarchical RVQ tokens (Mimi), and across three different model families, is the part that convinced us this is a property of the paradigm, not a quirk of one checkpoint.
One honest asterisk on this plot: best-of-N is a reference-aware selector (it uses the target transcript to score candidates), so it is an upper bound on what self-verification can buy, not a number you can deploy as-is. Which is the whole reason for the next step.
Paying for the fix once: distill the behaviour back in
Sampling N candidates at inference time costs N× compute. So we tried to remove that cost: fine-tune the model (a small LoRA) on its own self-verified best samples, so that ordinary single-shot decoding inherits the cleaner behaviour. No verifier at inference, no extra samples.
This is where the story gets more interesting and more honest. The distillation works, but only where there is room for it to work.
On the hard inputs (the ones where the base model is frequently wrong on the first try, but a good answer exists if you sample for it), a single distillation pass cuts the single-shot failure rate from about 0.20 down to 0.08–0.10, closing roughly half to three-fifths of the failure mass without paying the per-generation sampling cost. On easy prose, where the base model already succeeds almost always, there is simply nothing to recover: the rate doesn't move, and on a couple of models where the base was already near the floor, distillation even nudged it slightly worse.
We think the cleanest way to say it is: the distilled gain concentrates exactly where the model was failing. That is the useful, deployable version of the result. (We are also careful in the paper that our two test sets differ in more than just difficulty, so we flag difficulty as the most plausible explanation rather than a proven one, and we name the controlled experiment that would settle it. It is the honest read of a two-point comparison.)
The things that didn't work (the useful part)
A robustness paper that only reports what worked is hiding the evidence. Three negatives we think are worth more than they look:
- Fancier preference optimization didn't help. We expected offline DPO/IPO (train on a preferred sample versus a rejected one) to beat plain supervised fine-tuning on the good sample. It didn't. Across an offline sweep and a matched comparison, DPO and SFT were a tie, and the failure-targeted pairing we designed gave no edge. An online, iterative variant produced the single lowest number we saw, but on a small enough eval that its confidence interval overlaps everything else, so we report it as a promising direction, not a win. This lines up with a growing literature that offline DPO often doesn't beat SFT.
- Scaling up didn't buy robustness. The larger Llasa-3B was the one model where best-of-N didn't reach the floor, and where distillation regressed. We are upfront that its numbers carry a measurement caveat (we had capped its generation length to stop a hang, which can truncate long generations into failures), so we don't read the 1B-vs-3B gap as a clean scale effect, but "bigger" was conspicuously not "more robust."
- Some failures aren't sampling failures at all. Rare words (think otorhinolaryngologist) are a genuine capability ceiling: only 2 of 10 such prompts ever produced a faithful sample, no matter how many we drew. Best-of-N and distillation can only recover an answer the model is capable of; they cannot manufacture one it isn't.
What we're claiming
Catastrophic failures in neural-codec TTS are not an intrinsic price of the paradigm. A trivial test-time procedure (sample a few, verify with ASR, keep a good one) drives them to near-zero, and it does so across four models and three codecs, so it is a broadly shared property rather than a single-model quirk. A single distillation pass moves that fix's cost off the inference path (paid once in training rather than on every generation) on the hard inputs that dominate the failure budget. And the negatives (offline preference optimization adds nothing over SFT; scale didn't help; rare words are a capability wall) are, we think, as informative as the positives.
The whole study ran on Transformer Lab and cost on the order of 45 GPU-hours end to end, most of it on a single H100 at a time. Everything (the metric, the verifier, the distillation loop, and the four model backends) is reproducible from public models and public data; the numbers reproduce within the confidence intervals we report, since generation is stochastic by design.
Links
The full paper is on its way — we'll add the arXiv link here as soon as it's published.