Neither parallel nor sequential: how DiffusionGemma actually commits tokens

An inference-only interpretability study of a shipped diffusion language model: we hooked its own commit mechanism and watched the order it finalizes tokens in.
Quick summary: Our mental model of a diffusion language model assumes it fills text in parallel, all at once, independent of position. We instrumented Google's DiffusionGemma, without training or changing anything, to watch the order it actually finalizes tokens in. The surprise: it matches neither picture. It is not the clean parallel fill we assume, and it is not secretly left-to-right either — it has a partial, granularity-dependent bias, commits in big batches, and behaves differently depending on what you ask it to write. Separately, we found the model leans on an internal sense of confidence to finalize tokens early and stop generations ahead of its budget, and that confidence is a reliable signal of correctness in some domains (math) but not others (factual recall).
An autoregressive model writes one token at a time, left to right; our mental model of diffusion assumes the opposite — that it denoises a whole canvas of masked tokens at once, finalizing positions all over the output in parallel, in no particular order. That picture is the entire reason we expect a diffusion model to be faster. But the order a shipped model actually finalizes tokens in is a property of its trained weights and sampler, not a promise of the architecture, and nobody had measured it on a real released checkpoint.
So which picture does a real diffusion model resemble? To find out we took Google's DiffusionGemma (diffusiongemma-26B-A4B-it, an open-weights masked-diffusion mixture-of-experts model built on Gemma 4) and instrumented its own commit mechanism — without training or changing anything — recording exactly which canvas positions it freezes on each step and how confident it was when it did.
The surprise is that it is neither picture. DiffusionGemma is not the clean random fill we assume on the right, and it is not secretly left-to-right either. It has a partial, granularity-dependent left-to-right bias: moderate at the level of individual tokens, and looking more and more sequential the more you zoom out. It commits in big batches, it commits early and aggressively, and how it behaves depends on what you ask it to write. Structured JSON, notably, comes out close to order-independent.
There is also a story here about how the picture sharpened as we looked closer. A first read of this data suggested "block-autoregressive." A stronger run refined that into something more accurate, and we will walk through how, because the refinement is one of the most useful things in the study.
How we measured it, without touching the model
DiffusionGemma's sampler exposes a method, accept_canvas, that is called on each denoising step and decides which masked positions to finalize. That is the commit mechanism. We wrapped it with a forward hook that records, for every position, the first accept-call that commits it and the per-position entropy of the logits at that moment. No weights changed, no sampling decisions changed; the hook only watches. The whole study cost about 0.9 H100-hours.
Two facts about the resolution of this measurement shape everything downstream, so we want them up front rather than buried in a limitations section.
First, commit order is observed at accept-call resolution, and there are only about 3 to 17 accept-calls in a whole generation. Many positions get committed on the same call, and their order within that call is simply not observable. So "position p committed before position q" really means "on an earlier accept-call," not "one token earlier."
Second, we record the first call that commits a position. It turns out commits are not strictly frozen: across 600 generations we saw 4,524 cases of a committed position going back to masked (about 7.5 per generation), and only 220 of the 600 generations were fully monotone. So "commit order" precisely means first-acceptance order, and we had to check that the re-masking does not bias the conclusion (it does not; more below).
Our main metric is a tie-aware Kendall rank correlation (tau_b) between a token's commit-call index and its left-to-right position. Near +1 means strict left-to-right; 0 means order-independent; negative means right-to-left. We use the tie-corrected variant deliberately, because so many positions share a call that the ranks are heavily tied, and tokens committed on the same call are simultaneous, not out of order.
We ran six regimes: math (GSM8K), two code regimes (HumanEval and MBPP), short factual recall, open-ended instructions, and constrained JSON. We split each regime into an exploratory half (used to freeze every metric and threshold choice) and a confirmatory half (used only for the reported numbers), so the analysis choices could not be tuned on the numbers we report.
Looking closer: it is not block-autoregressive
An early two-seed run read the data as block-autoregressive: it looked like the model committed in left-to-right blocks of roughly 16 tokens, a clean and quotable story. It was worth a harder look before leaning on it.
So we ran a strengthening pass: five seeds, 20 prompts per regime, 600 generations, with a prompt-clustered bootstrap (resample prompts, keep their seeds together) so the confidence intervals respect the cross-seed correlation within a prompt. At that resolution, the "block" dissolves into something more interesting.
The "16-token block" was the tell. If 16 were the model's real architectural block, you would expect the order correlation to jump when you bin the analysis at 16. It doesn't. Sweeping the bin size from 4 to 64, the block-level tau_b rises smoothly and monotonically, with no jump anywhere near 16. For the math regime it goes 0.59, 0.64, 0.70, 0.79, 0.91 as the bin grows 4, 8, 16, 32, 64. Coarser bins look more sequential for the boring reason that they hide more within-bin disorder. 16 was an artifact of where we drew the bin, not a fact about the model.
That is the kind of detail that only shows up when you push the measurement harder. The finer-grained claim is the more accurate one, and it is the one worth reporting.
What it actually does
A partial, granularity-dependent left-to-right bias
At the token level, the order bias is real but moderate. Tie-aware tau_b runs from 0.43 to 0.60 across the prose, code, math, and factual regimes: positive, clearly above zero, but nowhere near the +1 of strict autoregression. Seed variance is small (the standard deviation of the mean across five seeds is 0.014 to 0.050), so these are stable numbers, not noise.
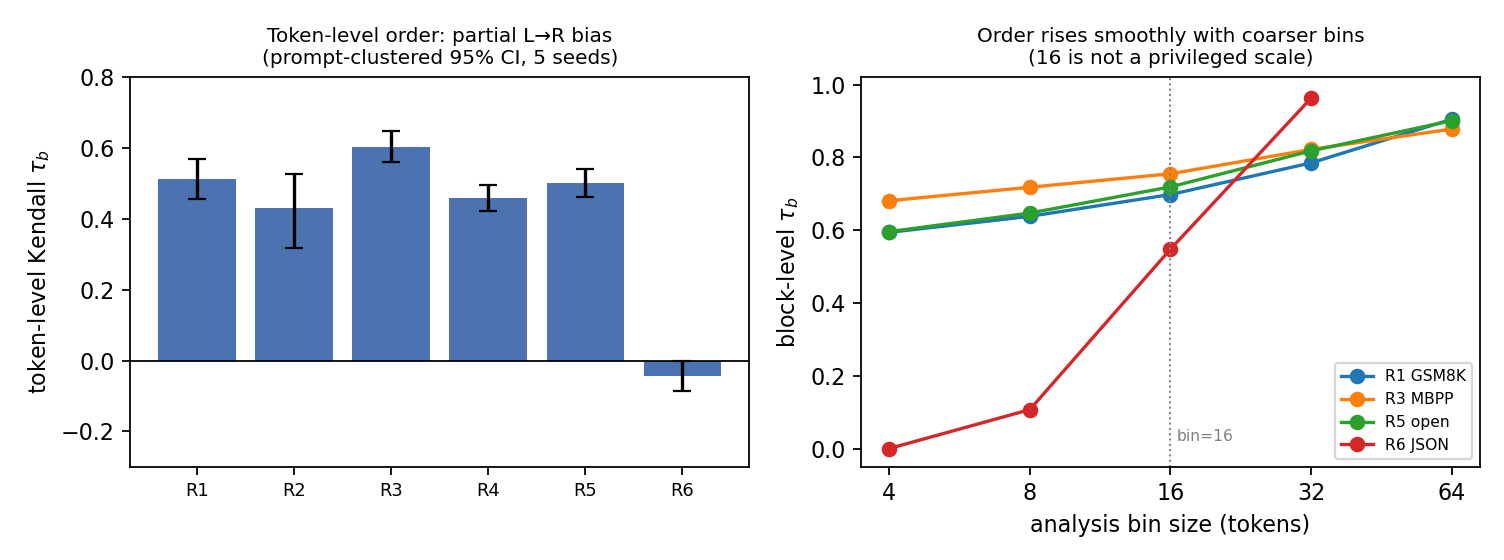
To put that 0.43-to-0.60 in context, we built a synthetic control: a pure block-sequential process (commit = position // 16, tied within block) that represents what clean block autoregression would score. The control lands at tau_b around 0.94 to 0.96. The real model sits far below it. That gap is the quantitative size of the genuine sub-block disorder; the model is reordering for real, not just committing in tidy left-to-right blocks.
| Regime | Task | Token tau_b [95% CI] | Block-seq. control | Tokens/call | Same-call |
|---|---|---|---|---|---|
| R1 | GSM8K (math) | 0.512 [0.456, 0.569] | 0.96 | 25.5 | 0.28 |
| R2 | HumanEval (code) | 0.430 [0.318, 0.527] | 0.94 | 23.0 | 0.49 |
| R3 | MBPP (code) | 0.604 [0.561, 0.647] | 0.96 | 19.8 | 0.19 |
| R4 | Factual | 0.460 [0.422, 0.496] | 0.41 | 5.8 | 0.50 |
| R5 | Open-ended | 0.502 [0.463, 0.542] | 0.96 | 12.6 | 0.11 |
| R6 | JSON | -0.044 [-0.086, -0.00] | 0.75 | 8.5 | 0.72 |
It commits in big batches
The "Tokens/call" column is part of why the token-level correlation stays moderate. The model commits 13 to 26 content tokens on a single accept-call in the prose/code/math regimes, and a large fraction of token pairs land in the same call (up to 0.72 for JSON). When that many tokens commit simultaneously, the within-batch order is just unresolved. The model is genuinely doing something more parallel than one-token-at-a-time, and the order we can see is a coarse, accept-call-level tendency.
JSON is the odd one out
Structured JSON output (R6) breaks the pattern entirely. Its token-level tau_b is -0.044, with the upper end of the confidence interval essentially at zero. So JSON is approximately order-independent: the model does not write it left to right, it places structural tokens where they need to go and fills around them. That lines up with the "anchor-first" reports in the literature, and it is a clean example of the order being a property of the task, not just the model.
Confidence predicts correctness on math, but not on facts
Separately from the decoding-order question, we looked at something the model appears to have arrived at on its own: an internal sense of confidence. It commits a token once the entropy at that position drops low enough, and it leans on this signal to finalize aggressively and stop a generation well before its step budget is up (more on that below). The signal is real and the model clearly uses it. The question we wanted to answer is how good a tool it is — when the model is confident about a token, is that token actually right? The answer is regime-specific, and this is another place where the stronger run sharpened the picture.
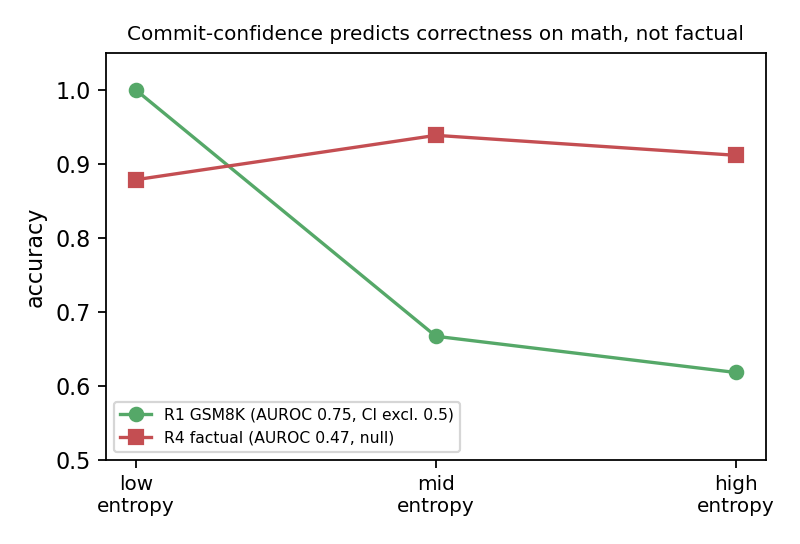
On math (GSM8K), confidence is informative: the AUROC of low-entropy-predicts-correct is 0.749 (prompt-clustered 95% CI [0.602, 0.879], which excludes chance), and the reliability curve is monotone, with accuracy falling as commit entropy rises. On factual recall it is a clean null: AUROC 0.471, CI [0.383, 0.544], which straddles 0.5, with flat reliability tertiles. With two seeds the factual signal looked strong; with five it settles to chance, so that early signal was small-sample noise.
To be precise about what "no better than chance" means here: the model is actually ~91% accurate on facts. What is chance-level is whether its own confidence tells you which answers it got wrong. On math, a confident commit really is more likely to be correct. On facts, the confidence carries no such signal.
There is a trap worth flagging. If you pool all regimes into one AUROC you get 0.437, below 0.5, which looks like "more confident means more often wrong." That is a Simpson's-paradox artifact: the regimes differ in both base accuracy and entropy scale, so the pooled correlation reverses the within-regime trend. It is a reason to always analyze this within regime, not a finding.
It stops early, well inside its own threshold
Despite a 48-step budget, generations finish in only about 3 to 17 accept-calls, tracking content length, and they commit at an entropy of 0.002 to 0.012 nats, one to two orders of magnitude below the sampler's own 0.1 entropy bound. The model is not cautiously using its full denoising budget; it commits content in a small, confident, late burst.
And it is about as accurate as its autoregressive sibling
On the three scorable regimes, DiffusionGemma's accuracy is comparable to the matched autoregressive Gemma-4 26B-A4B: roughly 0.66 to 0.73 vs 0.70 on math, 0.93 to 0.96 vs 0.967 on factual, and a tie at 1.00 on JSON. We did not power this as an equivalence test (about 30 prompts per cell, no confidence intervals on the differences), so read it as "comparable, not obviously worse," not as proven parity.
The measurement traps, because they will bite the next person too
A good chunk of this project was learning what not to measure, and these are the parts most likely to recur in anyone else's commit-order study:
- Trailing EOS padding. On the raw canvas the naive order metric gives
tau_baround -0.9, which would look like dramatic right-to-left decoding. It is an artifact: trailing end-of-sequence padding gets committed first and dominates the correlation. Restricting to content positions removes it. Every number we report is content-only. - Simpson's-paradox pooling, described above: pool across regimes and the confidence-correctness signal flips sign.
- Commit non-monotonicity. Because positions can re-mask, "commit order" is first-acceptance order. We re-ran the correlation on only the strictly monotone generations and got essentially the same numbers (e.g. math 0.579 vs 0.512), so the re-masking does not bias the conclusion, but it is a real model behavior worth studying on its own.
- Bin size is an analysis choice, not a model fact. This is the one behind the early block-autoregressive read. Report the sweep, not a single bin.
What we are claiming
DiffusionGemma decodes with a partial, granularity-dependent left-to-right bias, not clean block autoregression and not full parallelism. It commits in large batches, early and well inside its confidence threshold; its commit confidence predicts correctness on math but not on factual recall; and structured JSON comes out approximately order-independent. On accuracy it holds up against the autoregressive Gemma-4 sibling on the regimes we could score.
All of this is one checkpoint on one H100, with 20 prompts per regime, so it is a characterization and not the last word. tau_b is a rank correlation, not a claim about the model's internal reasoning, and we keep the language descriptive on purpose. The full writeup, Neither Parallel Nor Sequential: How DiffusionGemma Actually Commits Tokens, has the per-regime tables, the bin-size sweep, the block-sequential control, and the non-monotonicity check. There is no public release for this one; the instrumentation harness, the probe suite, and the recorded traces are available on request.
The thing we would most like to be useful is the lens itself: hooking a shipped sampler's own commit mechanism and watching what it does, rather than proposing a new decoding strategy. It is cheap, it is non-invasive, and it sharpened our own picture of the model, which is about the best you can ask of a measurement.
Links
- Full paper on arXiv: arxiv.org/abs/2606.14620