Making INT8 actually fast: a fused kernel for Ideogram 4 on a 3090

A custom fused INT8 GEMM that turns our Ideogram 4.0 INT8 build from the slowest variant into the fastest on consumer Ampere, and makes 1024px single-GPU.
Quick summary: Last week we shipped an INT8 build of Ideogram 4.0 that matched FP8 on quality but was, embarrassingly, the slowest of the three variants on a 3090. The reason was that the "INT8" path never actually used the GPU's INT8 hardware. We wrote one fused kernel that fixes that. INT8 goes from slowest to fastest, and a 1024px image now generates on a single RTX 3090.
Last week we quantized Ideogram 4.0 onto a 3090. The INT8 build held the FP8 quality ceiling and beat NF4, which is exactly what you want from a quantization. There was one embarrassing problem: it was the slowest of the three on a pair of RTX 3090s, 184 to 185 seconds per image against FP8's 172.9 and NF4's 164.5. The quality was right and the speed was wrong, which is a strange place to land for a method whose whole job is to make things faster.
This post is about why that happened and how we fixed it. The short version: the "INT8" path was never running on the GPU's INT8 hardware. We wrote one fused Triton kernel that keeps the multiply on the integer tensor cores where it belongs. On a single RTX 3090 that turns INT8 from the slowest variant into the fastest, 156.5 s/image at 1024px, ahead of both NF4 and FP8, and it fits on one card instead of two.
We are also going to be honest about the ceiling. The end-to-end win is about 9.5%, not the 3.5x you might expect from the kernel itself, and it only applies to consumer Ampere. On an A100 or a B200 the same kernel loses. We will explain both.
The paradox: INT8 was slower than the thing it replaces
The RTX 3090 sits on the wrong side of a hardware line. Ampere has fast native INT8 tensor cores but no FP8 or FP4 tensor cores at all. Anything that assumes an FP8 datapath quietly falls back to bf16 on these cards and gives up its advantage. So INT8 weight-and-activation quantization (W8A8) is the natural fit: it is the one low-precision format Ampere can run on dedicated integer hardware.
On quality our June build delivered. And then it lost on speed to the formats it was supposed to undercut. If you have spent the memory and accuracy budget to get to 8 bits, you should be getting compute back. We weren't.
The diagnosis: it was fake-quant the whole time
We went and read the forward path, and the cause was entirely a software one. The deployed "INT8" linear quantized the weights and activations to int8 and then dequantized them straight back to bf16 and called an ordinary bf16 F.linear. The integer tensor cores were never touched. What was labeled INT8 compute was really a round trip through int8 storage followed by bf16 arithmetic.
Once you see that, the slowness stops being mysterious. FP8 and NF4 at least run a single dense matmul. The "INT8" path ran a matmul plus an extra dequantization pass, so it was doing strictly more work than the baselines it was competing with. The entire compute advantage of the format was sitting on the table, unused.
The fix: one fused kernel that stays in integers
The fix is to make the integer tensor cores do the work. We wrote a single fused Triton GEMM that does the int8 x int8 to int32 accumulation on Ampere's mma.s8 units, and then, in the epilogue working directly off the int32 accumulator, applies the per-token activation scale, the per-channel weight scale, and the bias, emitting the dequantized result in one pass. The entire quantized linear becomes one kernel launch instead of a matmul followed by a separate dequant.
The one design point worth calling out: folding a dynamic per-token activation scale into the epilogue. The zero-overhead scale tricks that several W4A8 LLM kernels use assume static activation scales that can be baked into the weights offline. Our per-token scales are computed online, per forward pass, so they have to be applied in the epilogue off the accumulator. That is the part that does not come for free from existing recipes.
We did not touch the quantization recipe itself. The math is identical to the June build; the only difference is that the linears now run on integer hardware instead of bf16. The diffusion transformer makes this tractable: across its 34 layers and two classifier-free-guidance branches there are only five distinct GEMM shapes, so the autotuner has five shapes to sweep, not hundreds.
Autotuning was the difference, not a finishing touch
It would be easy to treat autotuning as a final 5% polish. It is not. Without it, the fused kernel beats bf16 by only 1.4 to 2.9x, and on the LLM-projection shape it is actually slower than bf16, at 0.64x. Autotuning over 36 configurations keyed per shape lifts every shape into the 2.8 to 4.2x band and turns that 0.64x regression into 3.65x.
| GEMM shape (N, K) | Fused vs. bf16 |
|---|---|
| qkv (13824, 4608) | 2.79–3.46x |
| attn-out (4608, 4608) | 2.86–3.76x |
| ffn-up (12288, 4608) | 2.78–4.18x |
| ffn-down (4608, 12288) | 2.94–3.51x |
| llm-proj (4608, 53248) | 2.95–3.17x |
Before any of this we checked the kernel was correct. The int8 x int8 to int32 accumulation is bit-exact against torch._int_mm, and the dequantized output matches the reference at cosine similarity 1.0 with no NaNs, on all five shapes. A fast kernel that quietly corrupts the image is worse than a slow correct one.
One measurement detail worth passing on: a thermally throttled 3090 measured about 8.1 bf16 TFLOPS against a healthy card's 65.5, a 6 to 8x difference. Since our headline is a ratio of fused to bf16, a throttled card would silently inflate it, so we gate every measurement behind a bf16 health check and only report numbers from cards that pass.
The headline: 1024px on a single RTX 3090
The per-GEMM win carries through to real generation. At 768px the fused build generates an image in 97.79 s against the fake-quant build's 107.06 s under an identical config, a roughly 9 to 10% speedup with quality holding.
The number we cared about most is 1024px, because that is where the fake-quant INT8 path needed two cards. The fused build generates a 1024px image in 156.5 s on a single RTX 3090, at a peak of 23.40 GB, which fits inside a 24 GB card.
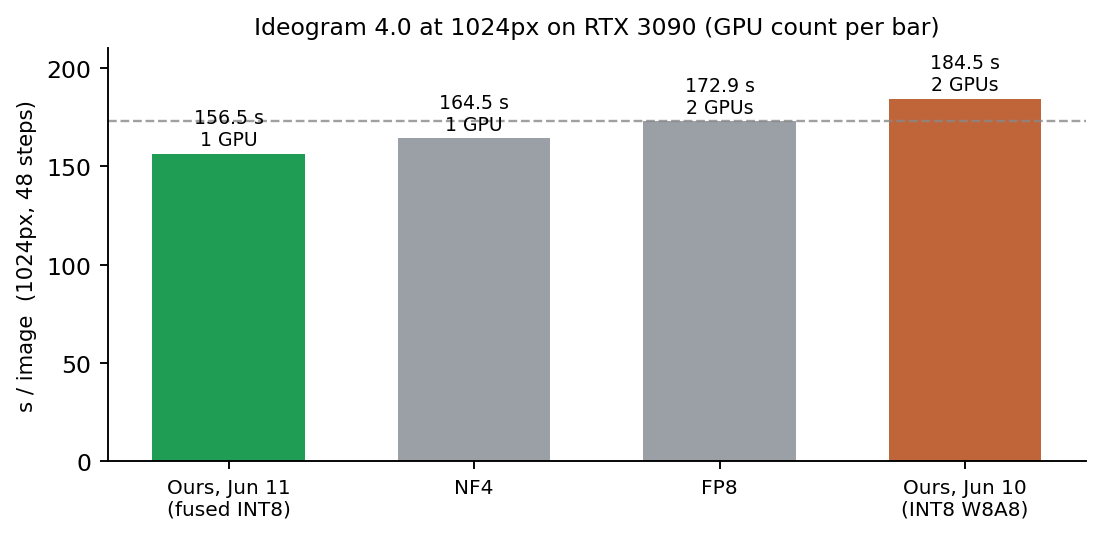
| Variant | s/image | GPUs | Note |
|---|---|---|---|
| FP8 (prior work) | 172.9 | 2 | dequant-to-bf16 on Ampere |
| NF4 (prior work) | 164.5 | 1 | |
| INT8 fake-quant (prior work) | 184–185 | 2 | quantize then dequant to bf16 |
| Fused INT8 (ours) | 156.5 | 1 | peak 23.40 GB, single card |
So INT8 goes from the slowest variant to the fastest, and 1024px becomes single-GPU feasible. Realizing the compute is also what fixed the memory: the single-card fake-quant path peaks around 26.7 GB and does not fit a 3090, while the fused build's 23.40 GB does. The speed win and the single-card feasibility are two faces of the same fix.
The honest ceiling: why 9.5% and not 3.5x
The kernel is about a 3.5x win per GEMM, but the end-to-end gain is only about 9.5%. That gap is worth understanding rather than burying. It is Amdahl's law: working back from the measured numbers, the DiT linear GEMMs are only about 12% of the forward pass. The other ~88% is attention, normalization, and sampling overhead, none of which this kernel touches. A 3.5x speedup on 12% of the work is a ~9.5% speedup overall, which is exactly what we measure.
We tried the two obvious ways to widen the win, and both are dead ends on this model today. torch.compile on the fused build gives effectively zero gain because the compiler graph-breaks at the custom linears. Swapping in SageAttention's INT8 attention is blocked outright: the DiT's head dimension of 256 exceeds the library's 128 limit, so it falls back to FP16 and gains nothing. Absent progress on those two fronts, ~9.5% is close to the ceiling for this approach on this model.
Where it does not work
The most important caveat is also the cleanest result, so we measured exactly where the win disappears. Running the same fused kernel against the same baseline at 1024px, on an A100 it is 1.38x slower and on a B200 it is 3.49x slower.
That is not a bug, it is the thesis turned around. Those cards have very fast native bf16 (about 216 TFLOPS on the A100, 587 to 610 on the B200), so the bf16 matmul they run is already extremely fast and the integer path has nothing to win back. The kernel is a win on consumer Ampere precisely because consumer Ampere has no fast native low-precision alternative.
So the deployment rule is simple: use the fused INT8 kernel when, and only when, the target lacks a fast native low-precision matmul, which is the consumer-Ampere case. On datacenter or Blackwell hardware, run the native bf16/FP8 path. Quality is unaffected either way; on the A100 the fused and fake-quant builds score within a hair of each other (PickScore 17.49 vs 17.54 on the 4-prompt subset).
What we are claiming, and what we are not
The primary criterion was to beat FP8, and we do, by about 9.5% (16 s) on one card versus FP8's two. The NF4 stretch margin is smaller, about 4.9% (8 s), and the latency numbers are single-run point estimates over a 4-prompt subset; we did not quantify run-to-run variance, so that margin is best read as consistent with beating NF4 rather than definitively beating it.
Two honest gaps. We did not re-measure the text-rendering OCR metric for the fused build; it is the most quantization-fragile number and it is carried over from the recipe. And our unfused baseline is the standard torch._int_mm two-step path, not a tuned vendor INT8 GEMM (cuBLASLt or CUTLASS); beating a tuned library kernel is left for later.
The whole study cost about 3 RTX 3090-hours of compute. The full writeup, including the per-shape microbenchmarks, the roofline analysis, and the hardware-specificity tables, is in the paper Realizing Native INT8 Compute for Diffusion Transformers on Consumer GPUs. The fused INT8 build is available as a gated, research-only checkpoint under the Ideogram 4.0 non-commercial license.
Links
- Full paper on arXiv: arxiv.org/abs/2606.14598
- Fused INT8 model (gated, Hugging Face): huggingface.co/transformerlab/ideogram-4-int8-fused
- Prior work (last week's quantization study): lab.cloud/blog/quantizing-ideogram-4 · arxiv.org/abs/2606.12280