Train anywhere. Track everything. Transformer Lab now runs on dstack.
· 5 min read

Transformer Lab now has built-in support for dstack. If your lab has GPUs scattered across clouds, on-prem boxes, or a mix of both, this improves how you run jobs.
Transformer Lab now has built-in support for dstack. If your lab has GPUs scattered across clouds, on-prem boxes, or a mix of both, this improves how you run jobs.
For many looking to experiment with machine learning, the biggest barrier to entry is access to hardware. GPUs are expensive, hard to find, and even harder to share across a team. Big cloud hosting providers have complex interfaces, pricing models, and try to lock you into their ecosystem and tooling.

Using Runpod with Transformer Lab changes that. Now you can spin up GPU-backed experiments quickly from the comfort of your own system.
Our open source research initiative recently closed a new round of funding and today, we launched the public beta for Transformer Lab for Teams: a modern operating system for AI research labs. It’s open source and free to use.

🎉 Transformer Lab just expanded beyond image diffusion! We're thrilled to announce text diffusion model support so you can train, evaluate, and interact with cutting-edge text diffusion architectures like BERT, Dream, and LLaDA directly in Transformer Lab.

When our team first started working on machine learning, we hit a wall. CUDA errors, broken Conda environments, and constantly breaking dependencies with PyTorch versions. We spent days just getting code to run, long before we could do anything interesting or innovative. Over time, I've learned this experience is incredibly common. Researchers have ideas but spend huge portions of their time just trying to make their work run.
And then comes the time to scale up. Moving a project to multiple GPUs can feel nearly impossible without an entire infrastructure team to help. This was our experience, and it's the core reason we started building this platform. We wanted to build the tool we wished we'd had from day one.
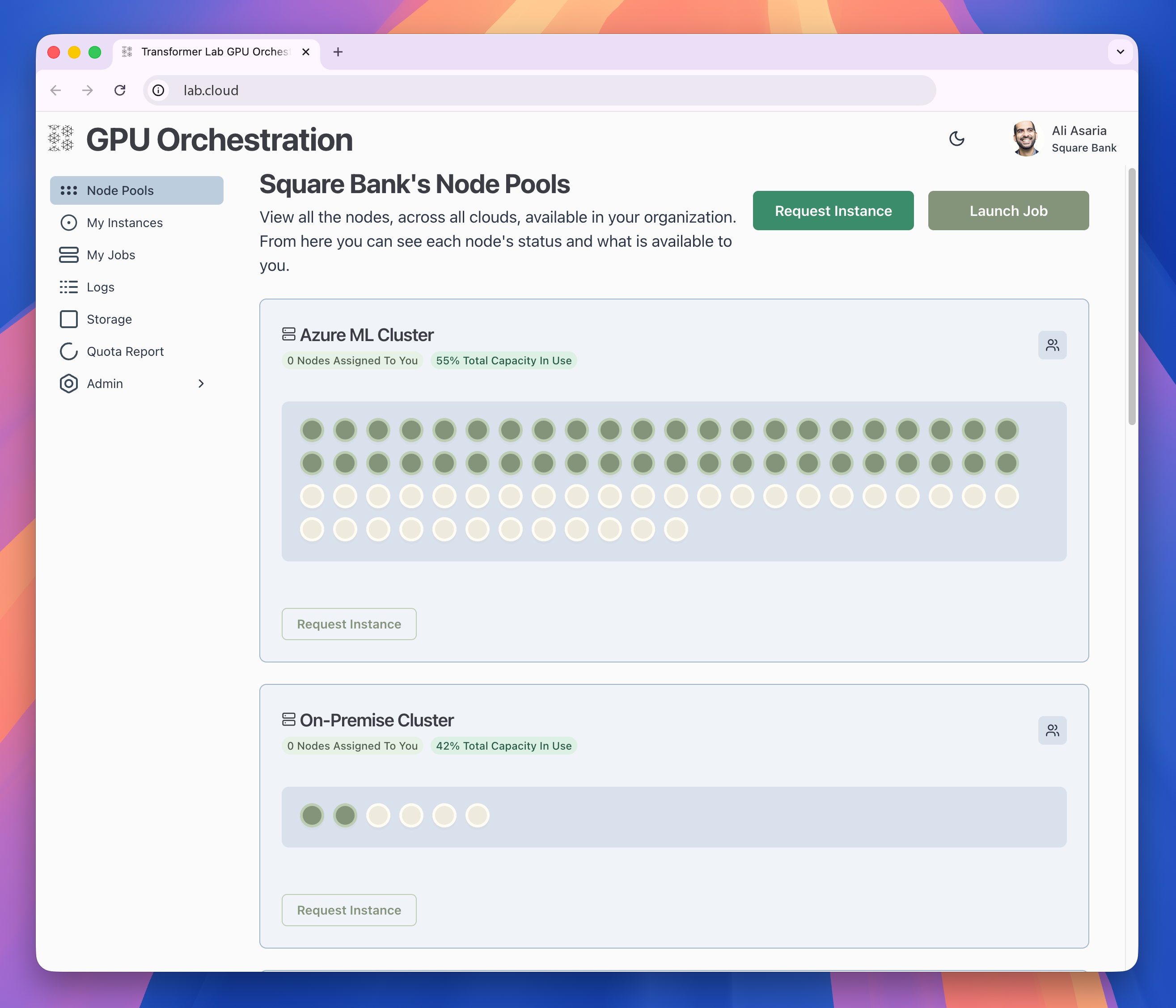
Today, we’re launching Transformer Lab GPU Orchestration, a flexible open-source platform for AI/ML teams to manage large-scale training across clusters of GPUs.

🎉 Transformer Lab just got a voice! We’re thrilled to announce audio modality support so you can generate, clone, and train voices directly in Transformer Lab.
kk, Transformer Lab now supports Diffusion image generation and training!
Out of the box we support major open weight base models including:
What can you do? Well...
We're excited to announce that Transformer Lab now supports AMD GPUs! Whether you're on Linux or Windows, you can now harness the power of your AMD hardware to run and train models with Transformer Lab.
👉 Read the full installation guide here
If you have an AMD GPU and want to do ML work, just follow our guide above and skip a lot of stress.
The journey for us to figure out how to build a reliable PyTorch workspace on AMD was... messy. And we've documented everything below.
We're excited to announce a significant enhancement to Transformer Lab - integration with the open-source Markitdown library from Microsoft! This update dramatically expands the types of documents you can work with in Transformer Lab, making it more versatile and powerful for your AI projects.