Diffusion LLM Trainer (Text Diffusion)
The Diffusion LLM Trainer plugin brings masked-language and diffusion-style alignment workflows into the Train tab. It builds on the dllm Python plugin format and supports CUDA hardware for training BertForMaskedLM, ModernBertForMaskedLM, DreamModel, and LLaDAModelLM architectures. Use it when you need quick SFT-style adaptation with Dream/CART weighting or lightweight LoRA adapters instead of full fine-tunes.
Step 1: Install the Plugin
- Open the
Pluginstab. - Filter by
Trainerand install Diffusion LLM Trainer. - Confirm the environment is configured for CUDA GPUs. CPU or TPU can be selected in the config, but training performance and plugin validation currently target CUDA.
note
If you plan to use multi-GPU, keep gpu_ids on auto to span every visible CUDA device, or enter a comma-separated list such as 0,1,2,3.
Step 2: Prepare Your Text Dataset
You can either download a dataset from the Hugging Face Hub or upload your own dataset.
To upload your own dataset:
- Go to the
Datasetstab and click New. - Choose Text and import a dataset that contains prompt/response style pairs or masked-language data.
Step 3: Create a Training Task
- Navigate to the
Traintab and click New. - Fill out the Template/Task Name, pick your dataset
- Switch to Plugin Config and review every section below.
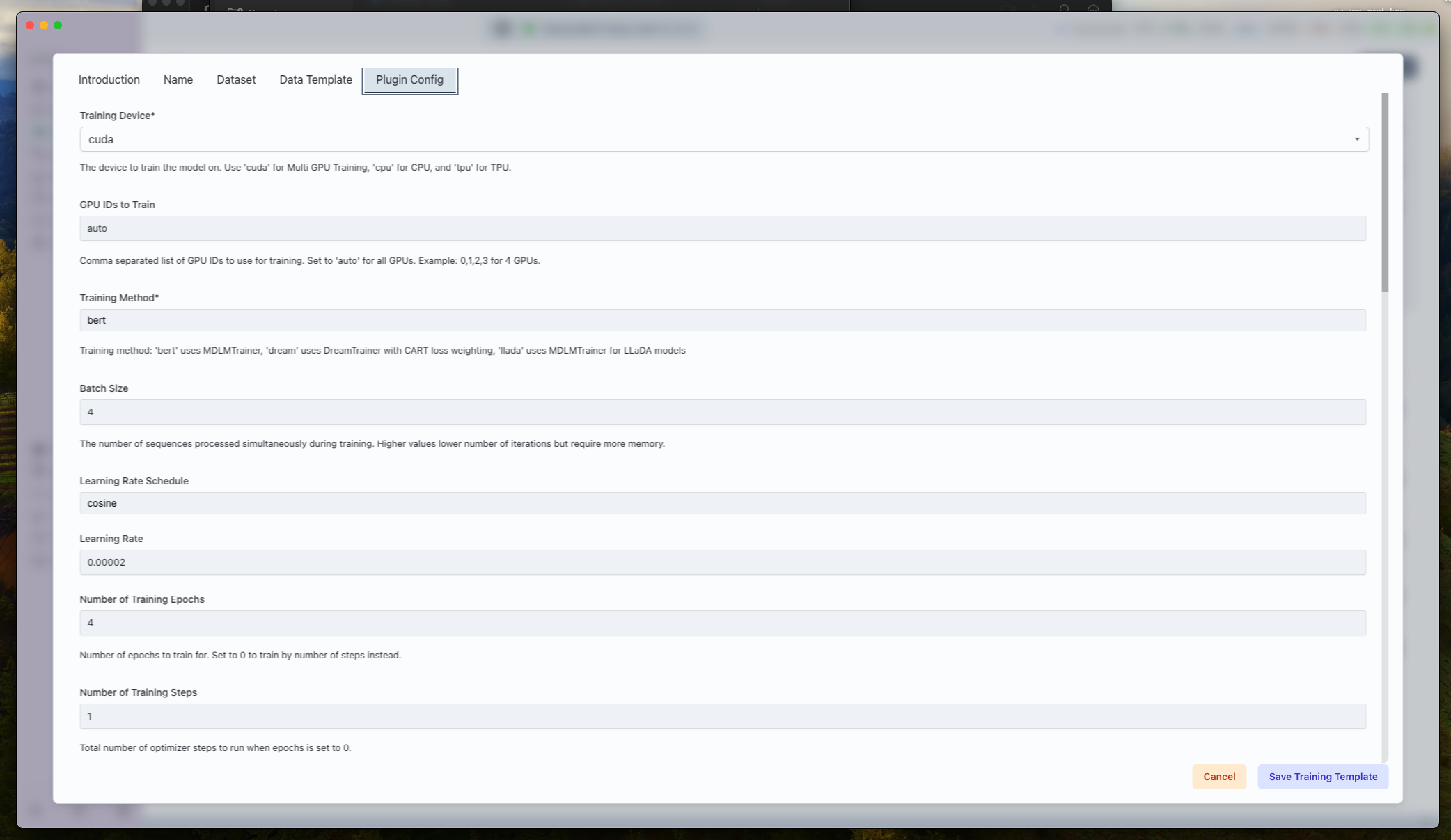
Core Execution Settings
- Training Device (
train_device): Choosecuda,cpu, ortpu. Usecudafor best throughput. - GPU IDs (
gpu_ids):autospans all visible GPUs; otherwise provide comma-separated IDs. - Training Method (
training_method):bert→ Use for Bert models likeanswerdotai/ModernBERT-largedream→ Use for Dream models likeDream-org/Dream-v0-Instruct-7Bllada→ Use for LLaDA models likeGSAI-ML/LLaDA-8B-Instruct
- Batch Size / Gradient Accumulation: Balance per-device memory vs. total effective batch.
- Sequence Length (
max_length): Cap sequences to manage VRAM. - Precision + Loading: Toggle
dtype,load_in_4bit, andlorato trade speed vs. quality.
Optimization Schedule
- Learning Rate (
learning_rate) and Scheduler (learning_rate_schedule) support constant, linear, cosine, and constant-with-warmup curves. - Warmup Ratio (
warmup_ratio): Fraction of total steps spent ramping LR. - Num Train Epochs / Train Steps: Set epochs to
0when driving via explicit step count. - Logging / Eval / Save Steps: Accept fractional values (e.g.,
0.25) to express percent of total steps; useful for long runs. - Gradient Accumulation Steps: Multiply with batch size to reach effective large-batch updates.
Parameter-Efficient Fine-Tuning
When lora is enabled:
- LoRA R (
lora_r) and LoRA Alpha (lora_alpha): Must be multiples of 4. - LoRA Dropout (
lora_dropout): Helps regularize long Dream runs.
Dream-Specific Controls
- Mask Prompt Loss: Disable to let prompts influence gradients (default masks prompts).
- Per-batch Cutoff / Response Cutoff Ratio: Randomly trims responses to reduce overfitting.
- Loss Weight Type: Choose
cart[geo_p:0.3]for CART-style decay orschedulerfor step-aware weighting.
Required Metadata
- Adaptor Name: Unique label for the saved adaptor.
- Logging: Keep
log_to_wandbon to mirror metrics in Weights & Biases.
Click Save Training Template once everything looks correct.
Step 4: Queue and Run the Job
- From the template detail view, press Queue.
- Watch the live logs. The runner will:
- Launch distributed workers on the selected GPU IDs
- Stream trainer logs, periodic evaluation, and checkpoint saves at
save_steps
Step 5: Monitor Training Metrics
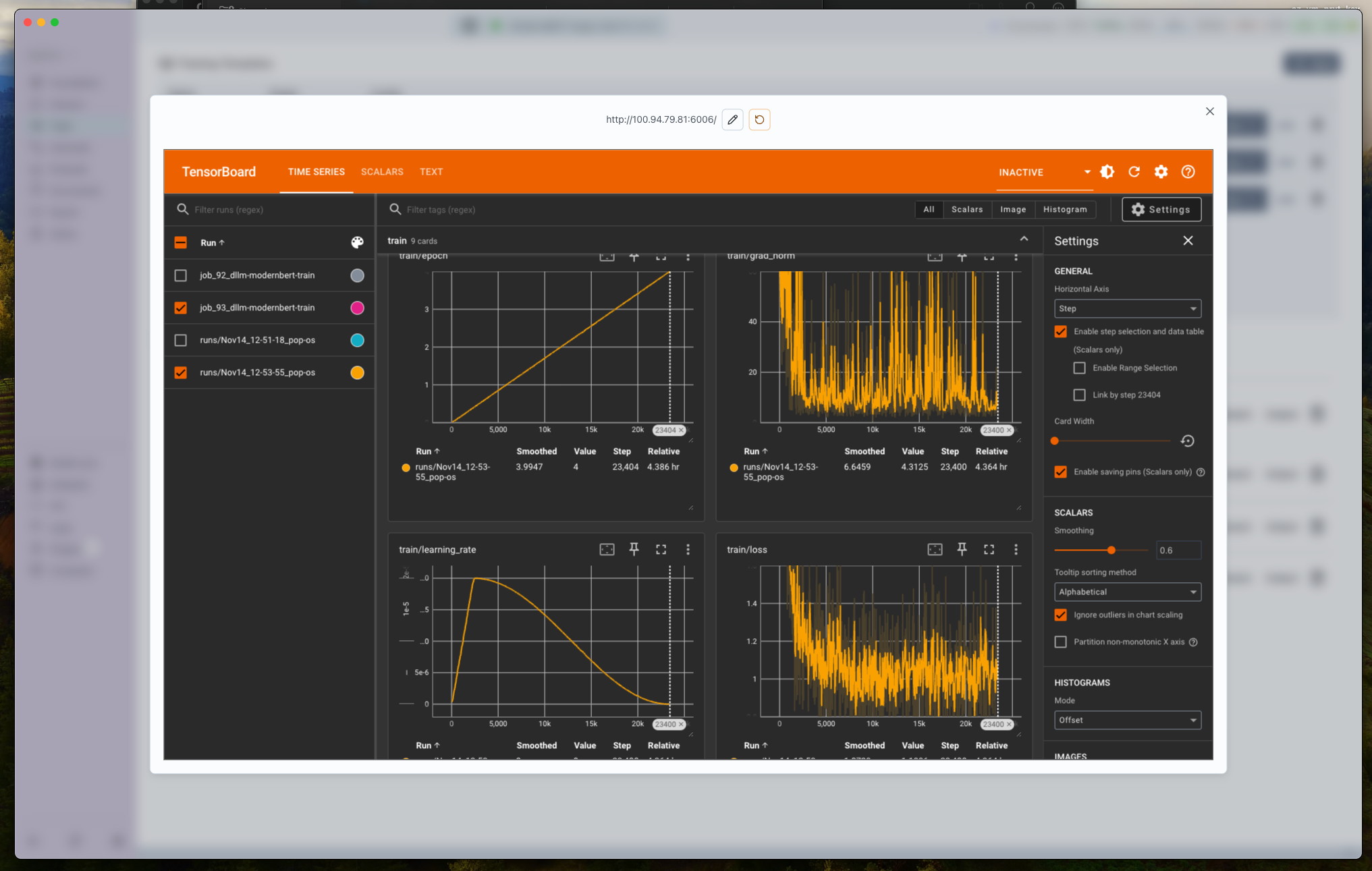
- TensorBoard: Open the sidebar log link to inspect loss and learning-rate curves directly in Transformer Lab.
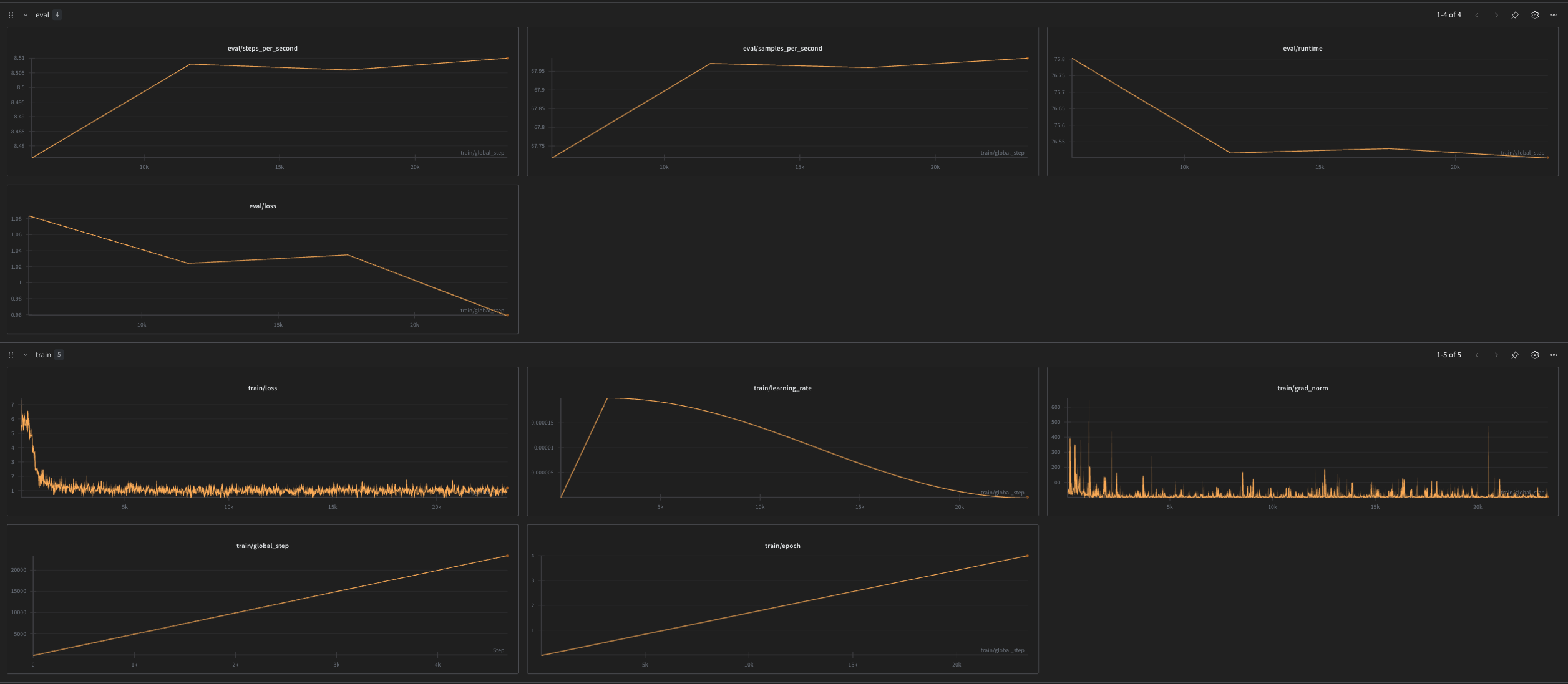
- Weights & Biases: If
log_to_wandbis enabled and your API key is set, you’ll see the run under the project configured in settings.
Step 6: Post-Training Outputs
- Dream/LLaDA runs automatically attach metadata about cutoff ratios and loss weighting, so you can track what worked best.
- You can view the final fused model in the Foundation tab.
Tips for Successful Text-Diffusion Runs
- Start with MDLM/BERT: Validate your dataset and template on
bertbefore jumping into Dream mode. - Dream Method Care: When
perbatch_cutoffis true, keepresp_cutoff_ratioconservative (0.0–0.2) to avoid truncating important supervision. - Sequence Budgeting: Shorter
max_lengthlowers memory use, enabling larger batch sizes or more GPUs. - LoRA vs. Full Fine-Tune: Enable LoRA for quick iterations; disable it for full-parameter adaptation when VRAM allows.
- Logging Discipline: Align
logging_steps,eval_steps, andsave_stepsso you always have checkpoints near the curves you analyze.