How I built my own Tesla-style self-driving AI

The moment I learned about the mechanics behind self-driving car technology, I was hooked. There’s a specific, geeky thrill that comes from realizing just how difficult and elegant this problem is—and I knew instantly that I had to try it for myself. Over the last few days, I finally carved out the time to dive in.
Disclaimer: I don't have a formal background in autonomous vehicle technology; this is my first foray into the space. I'm sharing this project in the hopes that it helps other hackers trying to build their first self-driving pipeline using public data!
Here are a couple of mind-bending things I learned about how Tesla's Autopilot AI actually works:
1. There is no intermediate representation:
When you drive a Tesla, the dashboard displays a beautiful 3D digital visualization of the car's surroundings. But the AI that actually drives the car does not use that map to steer. Tesla uses what is called a direct Vision-to-Action model. It is literally pixels in, actions out. The digital rendering of the traffic around you is drawn separately, purely for the human driver's peace of mind!
That blew my mind when I first realized it.

2. The models are smallll
The other crazy thing about in-car self-driving AI is that the models have to be small enough to run on an onboard GPU without draining the vehicle's battery. To put that in perspective, late-2024 Full Self-Driving (FSD) models were likely only 4–8B parameters in size.
This is also insane.
I wanted to tackle this Vision-to-Action problem myself to see how far one person with a single GPU could actually get. 🤪
What is a "vision-to-action" model, and why is it a cool problem?
A vision-to-action model takes raw perception (in this case, a camera image) and outputs a direct command (a steering angle) with no hand-designed intermediate steps in between.
Contrast that with a classic robotics pipeline:
- Detect objects
- Build a 3D map
- Plan a path
- Execute control
Each of those steps is a separate, human-engineered module. The end-to-end Vision-to-Action approach throws those modules out the window. Instead, it lets a single neural network learn the entire image-to-control mapping just by watching humans drive.
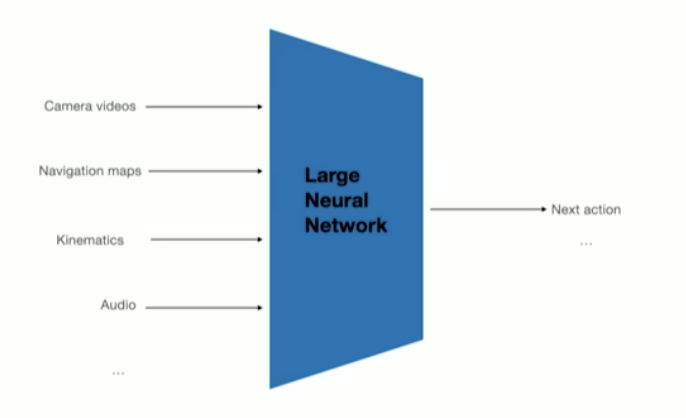
The fact that this could work is insane to me.
Step 1: Finding the dataset
Good news for hackers: comma.ai has released an incredible dataset for the community. The comma2k19 dataset contains about 33 hours of California highway driving. It’s recorded as ~1-minute segments with a forward-facing camera at 20 FPS, fully synchronized with car logs that include the exact steering-wheel angle at every given microsecond. It is public and MIT-licensed, making it the perfect playground. 🏆

The setup is clean. Each camera frame acts as an input, and the human's steering angle at that exact millisecond is the label the model needs to predict. Thousands of (image, steering-angle) pairs, straight from real-world drives.
Step 2: Architecting the rig
I deliberately kept my compute footprint small: a single GPU and a budget of roughly 100 GPU-hours. The goal was to prove the whole loop works end-to-end on a hobbyist-scale setup, not to throw a massive datacenter at the problem.
Could I design a system that can take images in and steering instructions out, and maybe do a decent job at it?
Here is the pipeline I built:
- Decode the compressed video into individual frames.
- Match each frame to the steering angle from the car's log by timestamp.
- Crucially: Split the data into training and testing sets by route, never by individual clip.
That last part is vital. Consecutive seconds of the same drive look virtually identical. If you split the data randomly, you leak near-duplicate frames into both your train and test sets, fooling yourself into thinking your model is a genius. Splitting by whole routes keeps the test honest.
Step 3: Picking the Metric
Testing a self-driving model isn't like grading a multiple-choice quiz. Steering isn't right-or-wrong; it's a smooth amount, like nudging the wheel a tiny bit versus cranking it hard into a turn. So "how often was it right?" doesn't really fit.
And there's a sneaky problem: almost all my driving footage (like 95% of it) is just the car cruising straight down the highway. That means a lazy model could basically cheat — always guess "straight ahead" — and still look amazing most of the time, even though it'd be useless the second the road actually curved.
At first I reached for the obvious scoreboard-style metrics. I tried plain average error (how far off the steering was, on average) — but that didn't make sense here, because with 95% straight roads, the lazy "always go straight" model scores great and I'd never catch that it can't turn. Then I tried R², a stat that's supposed to capture how well the model explains the steering overall — but that got thrown off too, since the rare turns skew it. Both basically rewarded the wrong thing.
So I switched to one called Pearson correlation, but measured only on the turns — the part that actually matters. It checks whether the model's steering rises and falls in sync with what the real driver did. The score goes from 0 (the model's guesses have nothing to do with reality) up to 1 (the model nails it, perfectly in step).
| Metric | What it measures | Did we use it? |
|---|---|---|
| Turn-slice Pearson correlation | On turns only — does the model's steering move in step with the real steering? | ✅ Yep — this is what I picked |
| Overall accuracy / average error (MAE) | How far off the model is, averaged across all frames | ❌ Nope — the 95% of "straight" frames let a lazy model look great without ever handling a turn |
| R² ("R-squared") | How much of the steering variation the model explains overall | ❌ Nope — misleading here, since the rare turns throw it off |
Step 4: Picking the right model
I dove into the research literature to see how the pros handle this. My understanding is that comma.ai uses a Convolutional Neural Network (CNN)—the traditional workhorse for image processing. Tesla, however, has transitioned to a Vision Transformer (ViT), the newer architecture dominating modern computer vision.
The conventional wisdom in the literature is blunt: ViTs are notoriously data-hungry. They lack the built-in assumption that CNNs have (that pixels near each other are related), so they require massive datasets to learn those relationships from scratch. On a small slice of driving data, the literature overwhelmingly predicts the CNN should win easily.
That made it the perfect hypothesis to test. But CNNs are BORING! Getting a Transformer model to work on a budget would be amazing. LET'S FIND OUT!
Step 5: the experiments (and the part that surprised me)
My first attempts made the ViT look exactly as data-hungry as advertised. The two most obvious things you would try first both flop:
- Freeze the pretrained ViT and only train a small head on top (a "linear probe"): turn-quality correlation of 0.38, basically "this thing cannot steer."
- Add the standard left-right image flip as data augmentation (mirror the picture, flip the sign of the steering): the model collapses to predicting a constant.
Initial Result: on my first tests, my ViT based rig sucked at steering (but a CNN based model worked). I was planning on giving up on Transformers.
😭😭😭😭
I started writing a blog post about how "transformers don't work on small driving data" (and why what Tesla does is out of reach for amateur developers) and started to move on. The breakthrough was realizing the problem was not the architecture, it was how I was adapting it. So I used the exact same ViT backbone (that failed badly), and tried three different ways of training it:
The first thing a practitioner tries. Reads as "the transformer cannot capture steering" — this is what makes a ViT look data-hungry.
Fine-tune the whole network at a gentle learning rate and the same model that scored 0.38 jumps to 0.96. 🥇🥇🥇🥇🥇 THAT'S GOOD. Nothing about the architecture changed. Only the adaptation did (and training with more data).
The other gotcha was an innocent-looking flip augmentation I added to the dataset. On normal image tasks, flipping is free extra data. But on this lopsided steering distribution it actively destroys the model by reinforcing "predict zero." The tell was a simple diagnostic: the spread of the model's predictions collapsing to nearly zero, even while the training loss looked fine.
With the flip on, the model predicts a near-constant angle: pred_sd collapses toward 0 and correlation is ~0, even though the training loss looks fine. Aggregate error would have hidden this — the dispersion diagnostic is what caught it.
Step 6: impressed by the results

It works! Above are night-time driving images with steering directions from my real trained model! 💃
Once adapted properly, the result genuinely surprised me. The supposedly data-hungry Vision Transformer matched the convolutional network at predicting steering, on as few as ~5,000 frames. On the turn slice (the part that matters), the ViT scored 0.964 and the CNN 0.967, a difference smaller than the run-to-run noise.
On the turn slice the two backbones are on top of each other and already near-ceiling (~0.96) at 5.2k frames — the ViT does not need more data to "catch up."
As far as I kno, there are no public rigorous research projects that compare these two models on real driving data. I'll publish an official report in the next couple days.
The headline is that if you are trying to experiment with working on self-driving car technology using ViTs, and you don't have access to a massive super-cluster, there are realistic pathways to getting valuable results.
Conclusion:
It worked: I got a ViT to learn to steer effectively on real roads with 0.96 Pearson score which is great.
And it points right back at the thing that hooked me. My model goes straight from vision to action with no scene in between, exactly like the direct controller I was fascinated by. A future next step, would be to add more controls (e.g. acceleration and braking). In the future I'd love to look into the direction the field (Tesla included) is heading, where they add a reasoning layer so the model can think about the scene before it acts, instead of only being able to reflexively map pixels to a steering angle.
For academia and industry this project proves that you CAN use ViT models on smaller datasets, so this whole setup can be used to test hypotheses for self-driving that would hopefully map to real-world applications.
You can try this too
If people are interested, I can upload the code for the end working project on Github. The full paper is here: It's the Adaptation, Not the Architecture.