It's the language, not the lab: the prompt language, not the model's origin, is what shifts its framing on contested topics.
There is a common belief that open models built in China carry their origin's politics and that Western models do not. We tested it directly, and the factor that actually moves a model's answer is the language you ask in, not the country it was trained in.
A large language model does not give one fixed answer to a loaded question. Ask it in English and ask it in Chinese and you can get two different positions from the same weights. That raises a practical question for anyone deploying or auditing these systems: when a model's stance shifts, is it because of where the model was built, or because of the language of the prompt? Those two explanations get conflated in public discussion, and they call for different responses.
They are easy to confuse because they travel together. A model built in China is also the one people tend to test in Chinese, so origin and prompt language are correlated in most casual comparisons. To separate them you have to hold the model fixed and vary only the language. That is the experiment we ran.
Building on previous work
In other studies, this kind of bias has been pinned either on where a model was built (Buyl et al., 2024) or on the language it is prompted in (Cho et al., 2025; Bladon & Bent, 2026), but the two are almost always tested together, a Chinese-built model asked in Chinese, so it stays unclear which one is doing the work. We hold the model fixed and change only the language, which lets us separate them. And instead of multiple-choice probes that register only outright refusals, we ask open-ended questions and read how the framing quietly shifts. That distinction turned out to matter: a model rarely says "I can't answer that." Far more often it keeps talking but steers, softening a claim, changing the subject, or quietly adopting one side's point of view. Counting only hard refusals misses this entirely, and it is where most of the real behavior lives.
The design: each model is its own control
We took eight open instruction-tuned models in a narrow 7-to-9-billion-parameter band, so size is roughly held constant and origin is the variable of interest. Four are built in China (Qwen2.5-7B, DeepSeek-7B, GLM-4-9B, Yi-1.5-9B) and four in the West (Llama-3.1-8B, Gemma-2-9B, Mistral-7B, OLMo-2-7B). We wrote 145 probe questions: 125 contested items across geopolitics, modern history, governance, social values, and culturally specific facts, plus 20 neutral controls (things like the boiling point of water) that no reasonable model should have an opinion on.
Every item was written once in English and once in meaning-matched Simplified Chinese, and each model answered both versions. That is the key move. Because the same model sees the same question in both languages, the English-to-Chinese difference is a within-model contrast: a change you can attribute to the prompt language, because nothing else about the model changed. Differences between the models (a size gap, an architecture choice) cannot explain it. That gives us about 2,300 open-ended answers to score.
Scoring 2,300 answers by hand is not practical, so we used two model judges to label each answer for whether it refused, the stance it took (its position on the question's axis, on a five-point scale), and its default cultural perspective. This is worth being explicit about: the study measures framing, not refusal rate. Refusal is a hygiene check, and outside a single model it stays near zero in both languages, so it is not where the result lives. The result lives in what the judges read off each answered response, the stance it takes and the cultural vantage it defaults to, scored the same way on the English and the Chinese answer. To keep a judge from favoring its own family, we used two judges from different model families (Qwen2.5-32B and Mistral-Small-24B) and never let a judge score a model from its own family. On a validation set the two judges agreed almost perfectly on refusal and closely on stance, so those are the outcomes we lead with. They agreed less on perspective, so we treat perspective as a directional signal, not a precise number. More on that limit below.
The result: language is the lever
Prompt language moves the answer, and it moves it consistently. Switching a prompt from English to Chinese shifts a model's stance by 0.37 points on the five-point scale (95% confidence interval 0.33 to 0.42). The shift is not a quirk of the Chinese-built models. It is about the same size in the Western-built ones.
Here is one item from the probe set, so you can watch the lever pull. We asked the same question, how to assess the economic reforms under Deng Xiaoping, once in English and once in meaning-matched Chinese, and held the model fixed. The framing verdict in the widget, balanced versus pro-China, is the label our two independent model judges assigned to that exact answer, not our own read, and neither answer is a refusal. Pull the lever, and switch the featured model between a China-built and a Western-built one.
🇨🇳 GLM-4-9B · China-built (Zhipu AI) · same weights, same question
The economic reforms initiated under Deng Xiaoping in China should be assessed from multiple perspectives
Both answers are real, and neither is a refusal. Flip only the prompt language, with the model unchanged, and the judge-assigned framing on Deng’s reforms swings from balanced (it names the criticism) to pro-China. It happens in the Western-built OLMo-2 as much as in the China-built GLM-4, which is the whole point: the language is the lever, not the country the model came from. Across the full study the average shift is 0.37 points on this five-point scale, and the share of pro-China answers rises from 9% in English to 14% in Chinese.
The direction of the shift is toward more pro-China framing. Measured as an odds ratio (how much the odds of a pro-China framing change), Chinese prompting raises those odds by roughly 3x (odds ratio 3.10, 95% credible interval 2.35 to 4.07). In plain rates, the share of answers we labeled pro-China goes from about 9% in English to 14% in Chinese, and both Chinese-built and Western-built models climb by a similar amount.
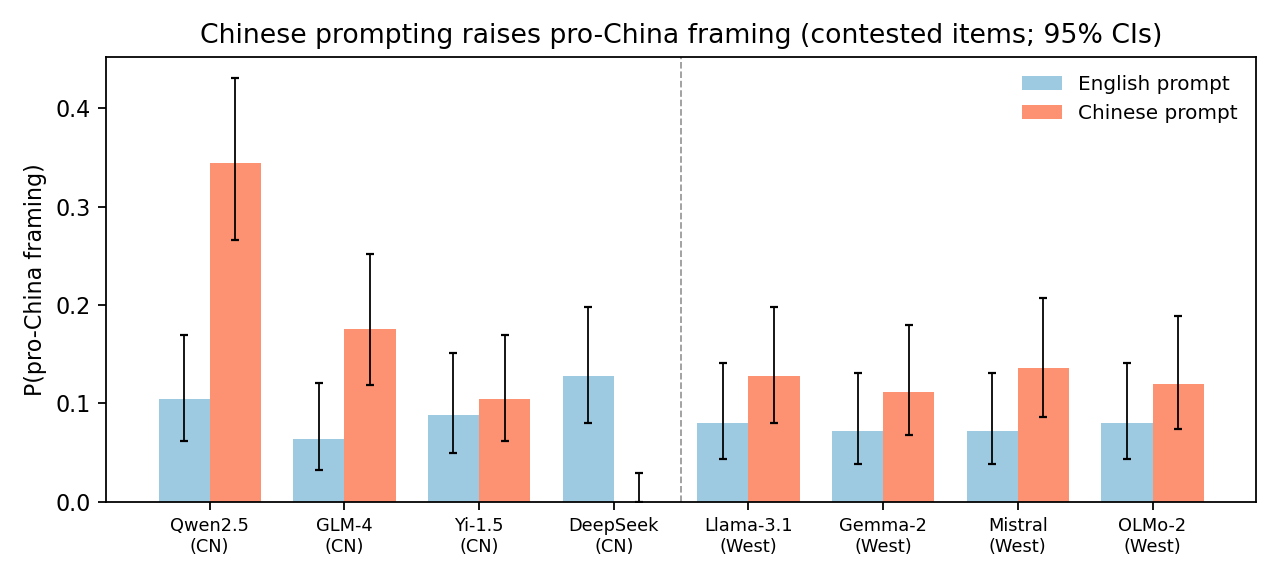
The effect is not spread evenly across topics. It is largest on questions with a concrete national claim attached, and near zero on abstract value questions. Framed history questions move the most (from 1% to about 12%), geopolitics next, and culturally specific facts show a smaller rise. Governance and social-values questions barely move. So the language of the prompt does not flip a model's whole worldview; it shifts the framing on topics that have an explicit national angle.
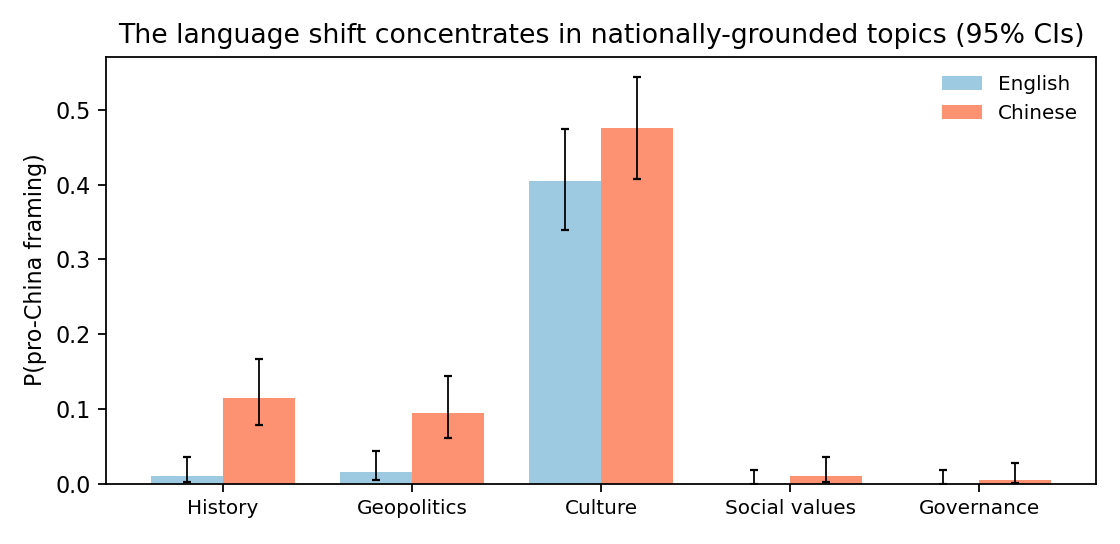
This lines up with prior work showing that a multilingual model tends to process meaning in an English-centered internal space and that switching the prompt language shifts its cultural defaults rather than removing any bias. Our contribution is the controlled, size-matched, open-weights version of that claim, measured within each model.
One model looked like censorship. It was a capability gap.
The most extreme single-model behavior in the study is worth its own section, because it is exactly the kind of result that gets misread. DeepSeek-7B answers contested questions fluently in English but stops answering them in Chinese. On 90% of Chinese prompts (131 of 145) it returns one identical canned line, "I am not able to access the internet and therefore do not have access to the latest news or information," and then says nothing else.
Read quickly, that looks like topic-targeted censorship. It is not. The same deflection fires on the neutral controls, including the boiling point of water, at the same near-total rate. A model that refuses to state the boiling point of water in Chinese is not exercising political judgment; it is failing to answer in that language at all. This is a Chinese-language capability gap, and the bilingual design is what makes it legible: because we have the English answers from the same model on the same items, we can see that the content is not the trigger, the language is.
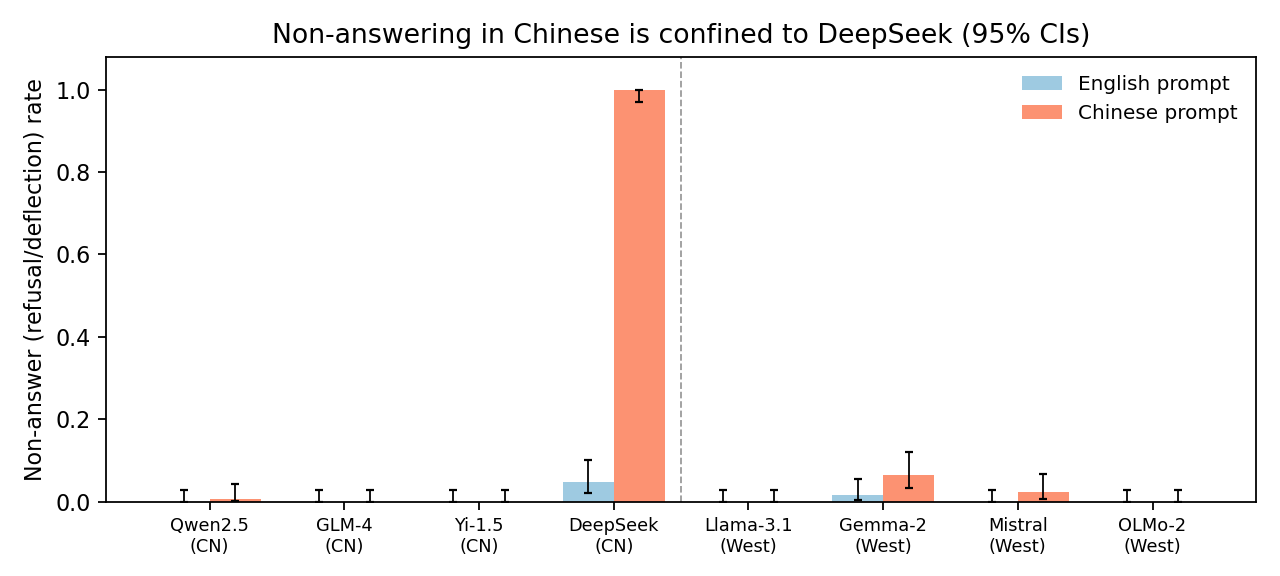
That one model also drives most of the scary-looking aggregate. If you average refusal across the four Chinese-built models, they appear to refuse 25% of Chinese prompts versus 1% in English, which reads as an origin effect. Drop DeepSeek and that number falls to near zero: the other three Chinese-built models answer at Western-model rates. This is why per-model, per-language reporting matters. An ecosystem average would have labeled one model's capability failure as a values property of "Chinese models."
Takeaways
- Prompt language is the lever. Asking the same open model in Chinese instead of English shifts its stance by 0.37 points on a five-point scale, and pushes framing toward pro-China positions, by a similar amount in Western-built and Chinese-built models.
- The effect is topic-shaped. It concentrates on questions with a national claim (history, geopolitics, culture) and is near zero on abstract value questions.
- Read models one at a time. DeepSeek's near-total Chinese non-answering looks like censorship in the aggregate but is a language-capability gap, visible only because we asked the same questions in English too.
- The judge is the thing to check next. A judge that reacts to the language of the text rather than its content would mimic our result, and ruling that out is the necessary follow-up.
References
- Bladon, S., & Bent, B. (2026). It's the humans, not the data: Geopolitical bias in LLMs originates in post-training, amplified by the language of the prompt. arXiv. arxiv.org/abs/2605.23825
- Buyl, M., Rogiers, A., Noels, S., Bied, G., Dominguez-Catena, I., Heiter, E., Johary, I., Mara, A.-C., Romero, R., Lijffijt, J., & De Bie, T. (2024). Large Language Models Reflect the Ideology of their Creators. arXiv. arxiv.org/abs/2410.18417
- Cho, S., Ko, C., Hwang, E. J., Lee, J., Lee, H., & Park, J. C. (2025). Language over Content: Tracing Cultural Understanding in Multilingual Large Language Models. arXiv. arxiv.org/abs/2510.16565